12 Auswerten: Modellieren
Versuchsplanung, Statistik, R, Datenanalyse, Psychologie, Forschung
12.1 Lernsteuerung
12.1.1 Lernziele
- Sie können die Modellformel Ihrer Forschungsfrage nennen.
- Sie können Ihre Modellformel (korrekt) in R spezifizieren.
- Sie können Ihr Modell in R berechnen und die Ausgabe interpretieren.
12.1.2 Benötigte R-Pakete
12.1.3 Position im Lernpfad
Sie befinden sich im Abschnitt “Auswerten” in Abbildung 1.2. Behalten Sie Ihren Fortschritt im Projektplan im Blick, s. Abbildung 1.3.
12.1.4 Weitere Lernmaterialien
12.1.4.1 Skript Bayes-Modellierung 📖
Die Grundlagen der statistischen Modellierung mit einem Fokus auf Bayes-Modellen können Sie hier nachlesen.
12.1.4.2 Videos 📽️
In einigen Playlists des Autors finden Sie Videos passend zu diesem Kapitel:
12.1.5 Überblick
In diesem Kapitel sind die grundlegenden Verfahren zur Modellierung und inferenzstatistischen Absicherung Ihrer Forschungsfragen angerissen. Die Darstellung zielt auf ein “so-geht’s” ab, nicht auf eine vollständige Darstellung aller Auswertungsmöglichkeiten.
Modellierung bedeutet, dass Sie Ihre Forschungsfrage(n) bzw. Hypothese(n) in ein statistisches Modell überführen. Praktisch gesehen heißt das, dass Sie ein Regressionsmodell der Art AV ~ UV1 + UV2 + ... aufstellen, s. Kapitel 10.7.
Welche bzw. wie viele UV sollte man in ein (Regressions-)modell aufnehmen? Nehmen Sie alle Variablen auf, von denen Sie annehmen, dass es Ursachen Ihrer AV sind. Berechnen Sie also nicht für jede UV ein eigenes Modell, sondern packen Sie alle UV in ein einziges Regressionsmodell. Das beinhaltet auch Konfundierungsvariablen und sonstige Ursachen der AV, die für Ihre Fragestellung nicht so interessant sind (wie Alter und Geschlecht), aber helfen, zu genaueren Schätzungen zu kommen. Variablen mit anderen kausalen Funktionen, wie Mediatorvariablen, sollten nicht in Ihr Modell aufgenommen werden, mit dem Sie den Effekt der UV auf die AV untersuchen.
Inferenzstatistik ordnet den Hypothesen eine Wahrscheinlichkeit zu und weist Punktschätzern einen Schätzbereich zu, s. Kapitel 10.7. Kurz gesagt: Inferenzstatistik bestimmt die Ungewissheit einer Schätzung.
Praktisch ist nicht viel zu tun für die Inferenzstatistik: Ihr Modellierungsbefehl (wie stan_glm oder lm) bereitet schon die Inferenzstatistik für Sie vor. Mit Befehlen wie parameters oder summary können Sie Ihrem Modell einfach die inferenzstatistischen Kennwerte entlocken.
12.2 1 between-Variable, nur Nachher-Messung
12.2.1 Design
Sauer & Lustig (2023) untersuchten in einer Querschnittsstudie den Effekt des Wirkstoff Bringnixtin auf die fluide Intelligenz. Die Autoren nahmen an, dass der Wirkstoff den individuellen Wert der abhängigen Variable erhöhen würde.
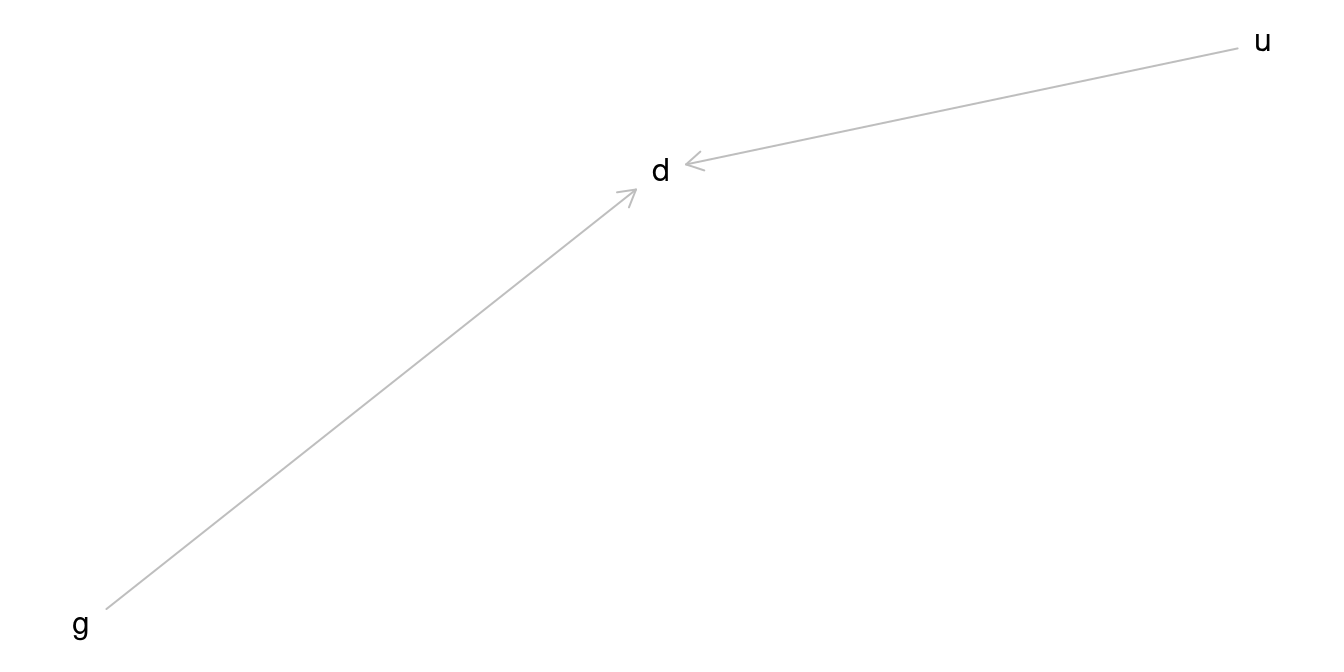
Der Ablauf (aus Sicht der Probandis) ist in Abbildung 12.1 dargestellt. Intro fasst die Begrüßung der Probandis inkl. Informed Consent sowie Erfassung von soziodemografischen Variablen zusammen. g.0 und g.1 sind die zwei Stufen der UV (g wie Gruppe), wobei g.0 die Kontrollgruppe kodiert (Placebo, also Zuckerpille, kein Wirkstoff,) und g.1 die zweite Stufe, d.h. die Experimentalgruppe (hohe Dosis Bringtnixtin). y2 ist die Messung der AV (d.h. nach Gabe von Bringtnixtin), d.h. ein Maß der fluiden Intelligenz. outro meint die Verabschiedung der Probanden sowie einige Fragen zu Compliance.
Die Hypothese lautet: \(\mu_{g.2} > \mu_{g.1}\).
In Worten:
Wir erwarten, dass der Mittelwert der Experimentalgruppe höher ist als der Mittelwert der Kontrollgruppe.
flowchart LR Intro --> g.0 Intro --> g.1 g.0 --> y2 g.1 --> y2 y2 --> outro
Der DAG des Experiments ist in Abbildung 12.2 dargestellt.

Im DAG Abbildung 12.2 ist u als Ursache von y2 angegeben. u steht hier stellvertretend für alle weiteren Ursachen von y2, vermutlich sind das sehr viele. Aber sie interessieren uns nicht. Daher können Sie u auch aus dem DAG weglassen. Streng genommen sollten Sie es sogar weglassen, denn im DAG zeigt man nur diejenigen Variablen, die für Ihre Hypothese von Belang sind. Da u keine Verbindung zum Pfad g -> y2 hat, brauchen wir es für die Bestimmung des Kausaleffekts nicht zu berücksichtigen.\(\square\)
Die Daten dieses Experiments sind hier zu beziehen:
d_bringtnixtin_path <- "https://raw.githubusercontent.com/sebastiansauer/fopra/main/data/d_bringtnixtin.csv"
d_bringtnixtin <- read_csv(d_bringtnixtin_path)Die Autoren der Studie geben an, dass die Daten in z-Einheiten skaliert sind.
12.2.2 Deskriptive Analyse
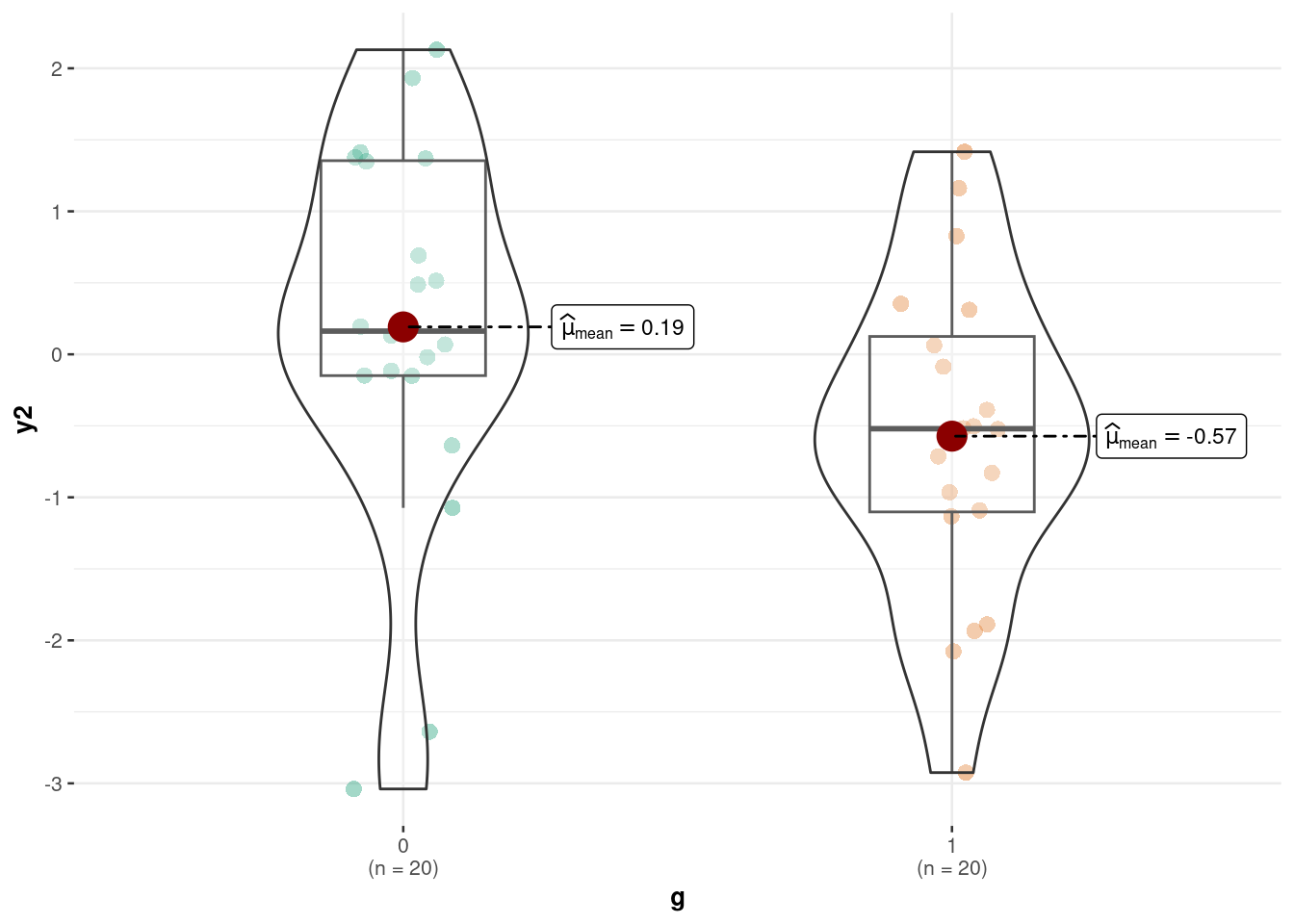
Die deskriptiven Kennwerte sind in Abbildung 12.3 bzw. Abbildung 12.3 visualisiert. Das sieht nicht gerade nach einem großen Effekt aus …1
ggbetweenstats(
data = d_bringtnixtin,
x = g,
y = y2,
results.subtitle = FALSE # keine Statistiken zeigen
)
ggboxplot(
data = d_bringtnixtin,
x = "g",
y = "y2",
add = "mean"
)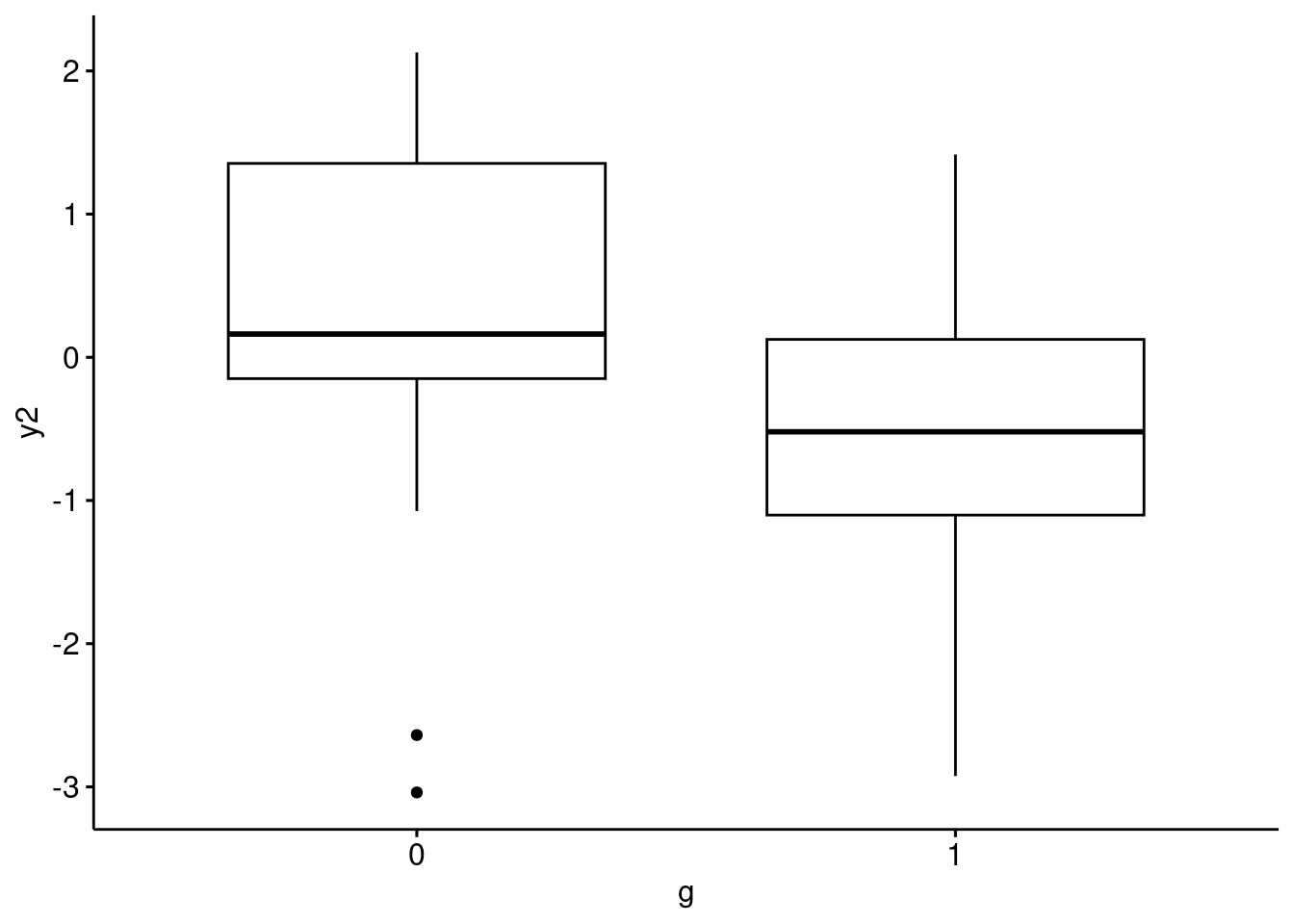
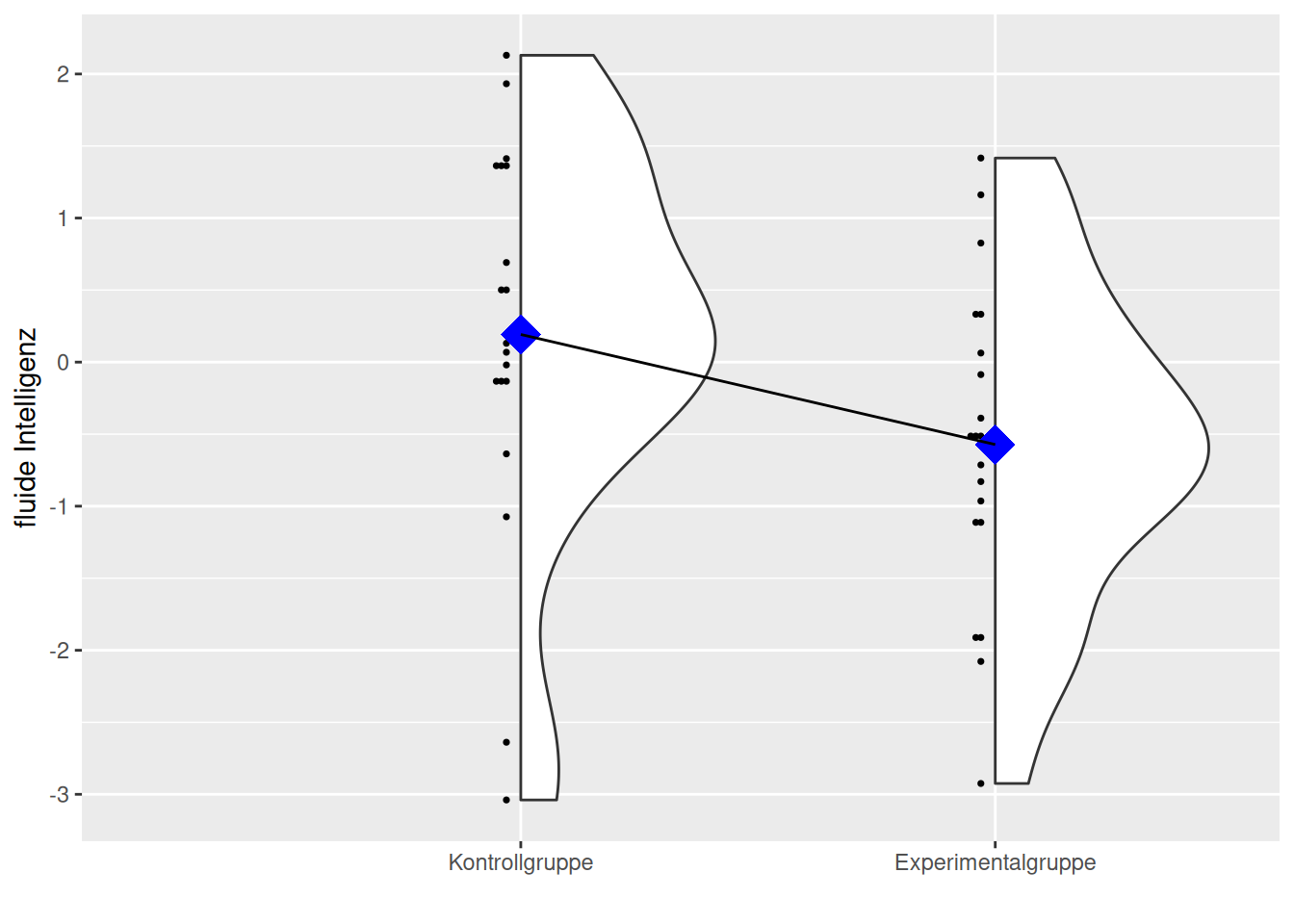
Sowohl das R-Paket ggstatsplot als auch das R-Paket ggpubr bieten ansprechende Datenvisualisierung. Beide bauen auf dem R-Paket ggplot auf, sind also eigentlich nur “Abkürzungen”.
Der Effekt einer UV bemisst sich am (mittleren) Unterschied in der AV zwischen den Gruppen.
12.2.3 Modellierung und Inferenz
Wir berechnen ein lineares Modell mit der Modellformel y2 ~ g.
12.2.3.1 Parameterschätzung
Die Ergebnisse unseres Modells m_bringtnixtin sind in Tabelle 13.5 zu sehen.
m_bringtnixtin <- stan_glm(y2 ~ g,
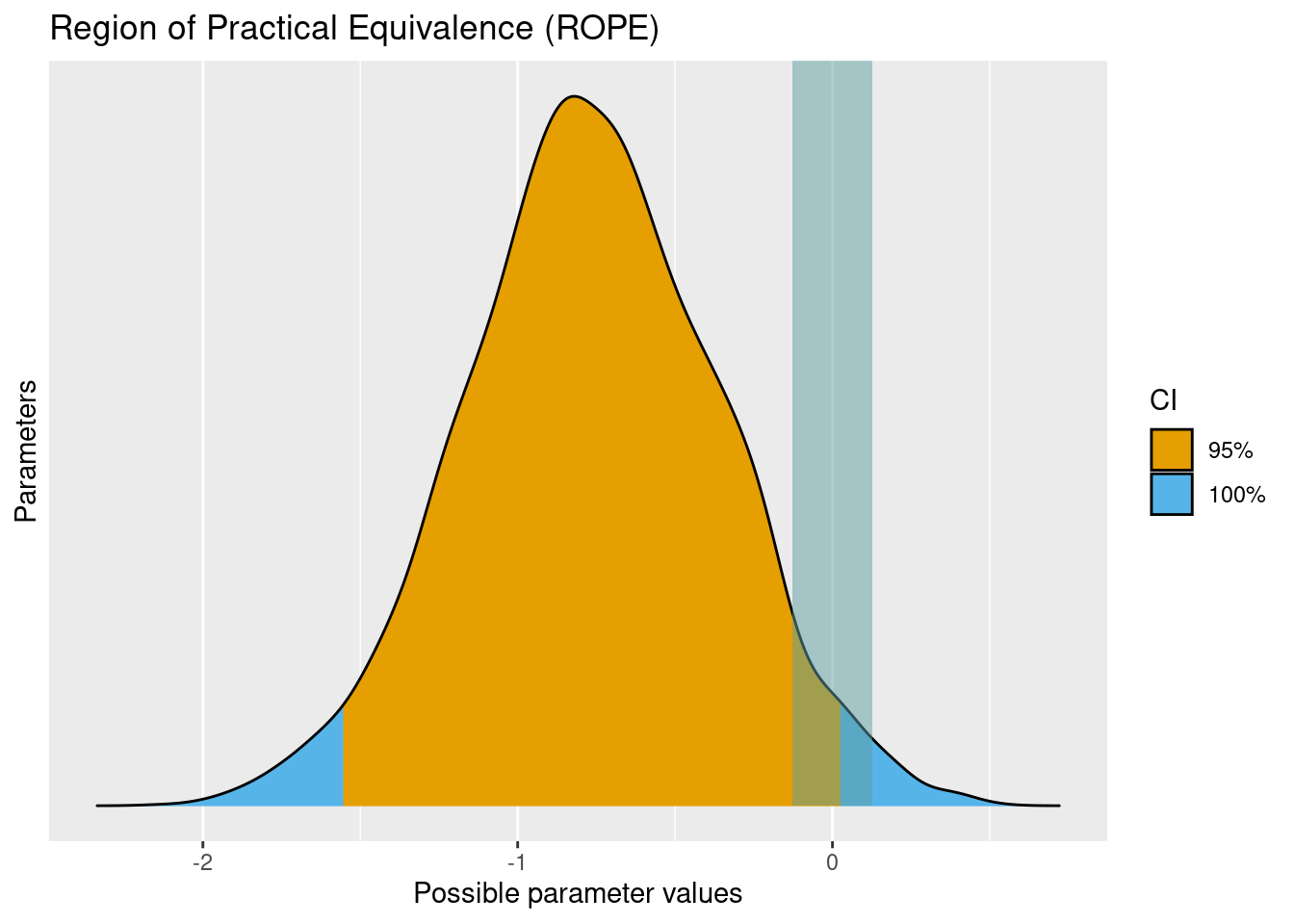
data = d_bringtnixtin)parameters(m_bringtnixtin)Der Gruppenunterschied wird auf das -0.75 geschätzt; das ist der Punktschätzer der UV g. Wenn wir nur eine Zahl nennen dürften zu unserem Wissen zum Effekt von g, so wäre das unsere Zahl. Die Grenzen eines 95%-CI für die UV liegen bei -1.56 bzw. 0.01; diese beiden Werten markieren die Grenzen des Intervallschätzers. Dieser Bereich enthält die Null, vgl. Abbildung 12.6. Daher kann nicht ausgeschlossen werden, dass Bringtnixtin nix bringt. Anders gesagt: Die (strenge) Nullhypothese kann nicht verworfen werden. Der Wert Null ist ein plausibler Wert für den Parameter, da er im 95%-CI enthalten ist.
- Ist der Wert Null NICHT im 95%-Schätzintervall enthalten, so heißt das, dass die Null(hypothese) verworfen werden.
- Ist der Wert Null im 95%-Schätzintervall enthalten, so heißt das, dass die Null(hypothese) NICHT verworfen werden. \(\square\)
Die Punkt- und Intervallschätzer (95%-ETI) für Achsenabschnitt und Regressiongewicht von g sind in Abbildung 12.6 visualisiert.
Zur Erinnerung: Ein Punktschätzer schätzt einen (unbekannten) Wert in der Population auf einen einzelnen Wert (daher “Punkt”). Ein Interschätzer schätzt einen Wertebereich für diesen unbekannten Wert. \(\square\)
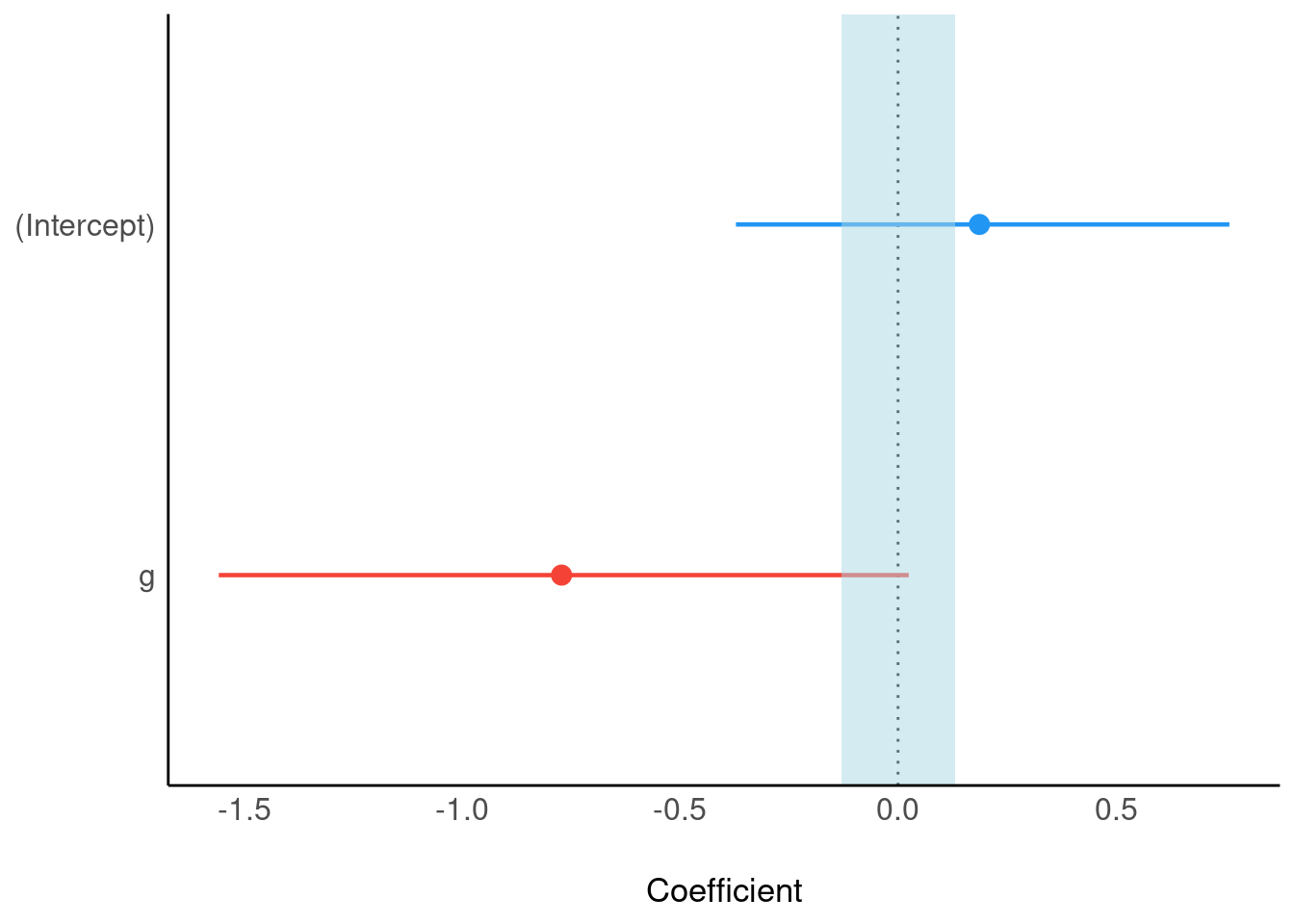
m_bringtnixtin (95%-ETI); der ROPE ist als vertikaler blauer Balken markiert
👨🏫 Frau Professor Lustig, wie kann das sein, dass sich die Hypothese nicht bestätigt?
👩🏫 Herr Professor Sauer, auch ein negatives Ergebnis bringt die Wissenschaft weiter.
12.2.3.2 Praktisch-Null-Hypothese (ROPE)
Definition 12.1 (Praktisch-Null-Hypothese (ROPE)) Kurz gesagt wird beim ROPE geprüft, welcher Anteil des Posteriori-Intervalls zu einem Bereich “vernachlässigbar kleiner” Parameterwerte bewegt (Kruschke, 2018). \(\square\)
Mit dem ROPE-Verfahren kann man eine “Praktisch-Null-Hypothese” testen, also ob ein Bereich um die Null herum, also “Null plus-minus ein bisschen” im Hauptbereich im Hauptbereich (95%-KI) enthalten ist.
Schauen wir uns die Umsetzung in R anhand des Beispiels zu Bringtnixtin an: rope(m_bringtnixtin), s. Tabelle 12.3 und Abbildung 12.7.
| Parameter | CI | ROPE_low | ROPE_high | ROPE_Percentage | Effects | Component |
|---|---|---|---|---|---|---|
| (Intercept) | 0.95 | -0.13 | 0.13 | 0.30 | fixed | conditional |
| g | 0.95 | -0.13 | 0.13 | 0.03 | fixed | conditional |
Tabelle 12.3 zeigt uns, dass 3% des 95%-HDIs im ROPE-Bereich liegt. Das ist nicht viel; aber streng genommen heißt das als Fazit:
Wir können nicht ausschließen, dass der Effekt von
gein praktisch unbedeutsamen Wert hat, also sehr klein und nahe der Null ist. Diese Wahrscheinlichkeit ist allerdings nicht hoch. Es ist somit keine klare Entscheidung möglich.
Ist man sich nicht sicher, wie der ROPE-Wert zu interpretieren ist, kann man auch R fragen:
interpret_rope(0.03)
## [1] "undecided"
## (Rules: default)Das gleiche Ergebnis zeigt uns anschaulicher Abbildung 12.7.
m_bringtnixtin
scale_fill_okabeito() ist eine Funktion aus dem Metapaket easystats.2 Das Farbschema nach Okabe und Ito ist gut geeignet, um nominal skalierte Farben zu kodieren (s. Details hier).
Da sich das 95%-CI mit dem ROPE überlappt, kann die Nullhypothese bzw. das ROPE (kein praktisch bedeutsamer Effekt) nicht ausgeschlossen werden.
Eine vergleichbare Information bietet uns die Kennzahl pd, s. Tabelle 13.5. Der Wert für g liegt bei ca. 0.97.
pd gibt die Wahrscheinlichkeit (laut Modell) an, dass der Effekt in der Population negativ bzw. positiv ist (d.h. gleich dem Vorzeichen des Punktschätzers; in diesem Fall negativ).\(\square\)
Das Modell ist sicher ziemlich sicher, dass der Effekt von g (in der Population) negativ ist. Aber eine kleine Chance, dass der Effekt von g doch (ungefähr) Null oder sogar positiv ist, bleibt.
👨🏫 Frau Professor Lustig, oh je! Unser Wirkstoff Bringtnixtin bringt anscheinend gar nix!
👩🏫 Herr Professor Sauer, wir müssen erst einmal in Ruhe die Studie replizieren. Eine Schwalbe macht noch keinen Frühling.
Beispiel 12.1 (Hat die Zylinderzahl einen Praktisch-Null-Effekt auf den Spritverbrauch?) Abbildung 12.8 illustriert ein Rope für die Forschungsfrage “Hat die Zylinderzahl einen Praktisch-Null-Effekt auf den Spritverbrauch”. Anders formuliert “Ist der Effekt der Zylinderzahl (auf den Spritverbrauch) vernachlässigbar klein?” Genauer gesagt ist die Posteriori-Verteilung für den (Regressions-)Effekt, \(\beta\), des Parameters cyl gezeigt (Datensatz mtcars). Wie man sieht, ist die Posteriori-Verteilung (roter Bereich; glockenförmige Verteilung) komplett außerhalb des Bereichs “sehr kleiner” Werte (ROPE; blaues Rechteck rechts). Wir resümieren: “Es ist auszuschließen, dass der Effekt der Variable Zylinder auf den Spritverbrauch praktisch Null (sehr klein) ist”. \(\square\)
##
## SAMPLING FOR MODEL 'continuous' NOW (CHAIN 1).
## Chain 1:
## Chain 1: Gradient evaluation took 1.7e-05 seconds
## Chain 1: 1000 transitions using 10 leapfrog steps per transition would take 0.17 seconds.
## Chain 1: Adjust your expectations accordingly!
## Chain 1:
## Chain 1:
## Chain 1: Iteration: 1 / 2000 [ 0%] (Warmup)
## Chain 1: Iteration: 200 / 2000 [ 10%] (Warmup)
## Chain 1: Iteration: 400 / 2000 [ 20%] (Warmup)
## Chain 1: Iteration: 600 / 2000 [ 30%] (Warmup)
## Chain 1: Iteration: 800 / 2000 [ 40%] (Warmup)
## Chain 1: Iteration: 1000 / 2000 [ 50%] (Warmup)
## Chain 1: Iteration: 1001 / 2000 [ 50%] (Sampling)
## Chain 1: Iteration: 1200 / 2000 [ 60%] (Sampling)
## Chain 1: Iteration: 1400 / 2000 [ 70%] (Sampling)
## Chain 1: Iteration: 1600 / 2000 [ 80%] (Sampling)
## Chain 1: Iteration: 1800 / 2000 [ 90%] (Sampling)
## Chain 1: Iteration: 2000 / 2000 [100%] (Sampling)
## Chain 1:
## Chain 1: Elapsed Time: 0.014 seconds (Warm-up)
## Chain 1: 0.013 seconds (Sampling)
## Chain 1: 0.027 seconds (Total)
## Chain 1:
##
## SAMPLING FOR MODEL 'continuous' NOW (CHAIN 2).
## Chain 2:
## Chain 2: Gradient evaluation took 4e-06 seconds
## Chain 2: 1000 transitions using 10 leapfrog steps per transition would take 0.04 seconds.
## Chain 2: Adjust your expectations accordingly!
## Chain 2:
## Chain 2:
## Chain 2: Iteration: 1 / 2000 [ 0%] (Warmup)
## Chain 2: Iteration: 200 / 2000 [ 10%] (Warmup)
## Chain 2: Iteration: 400 / 2000 [ 20%] (Warmup)
## Chain 2: Iteration: 600 / 2000 [ 30%] (Warmup)
## Chain 2: Iteration: 800 / 2000 [ 40%] (Warmup)
## Chain 2: Iteration: 1000 / 2000 [ 50%] (Warmup)
## Chain 2: Iteration: 1001 / 2000 [ 50%] (Sampling)
## Chain 2: Iteration: 1200 / 2000 [ 60%] (Sampling)
## Chain 2: Iteration: 1400 / 2000 [ 70%] (Sampling)
## Chain 2: Iteration: 1600 / 2000 [ 80%] (Sampling)
## Chain 2: Iteration: 1800 / 2000 [ 90%] (Sampling)
## Chain 2: Iteration: 2000 / 2000 [100%] (Sampling)
## Chain 2:
## Chain 2: Elapsed Time: 0.013 seconds (Warm-up)
## Chain 2: 0.014 seconds (Sampling)
## Chain 2: 0.027 seconds (Total)
## Chain 2:
##
## SAMPLING FOR MODEL 'continuous' NOW (CHAIN 3).
## Chain 3:
## Chain 3: Gradient evaluation took 4e-06 seconds
## Chain 3: 1000 transitions using 10 leapfrog steps per transition would take 0.04 seconds.
## Chain 3: Adjust your expectations accordingly!
## Chain 3:
## Chain 3:
## Chain 3: Iteration: 1 / 2000 [ 0%] (Warmup)
## Chain 3: Iteration: 200 / 2000 [ 10%] (Warmup)
## Chain 3: Iteration: 400 / 2000 [ 20%] (Warmup)
## Chain 3: Iteration: 600 / 2000 [ 30%] (Warmup)
## Chain 3: Iteration: 800 / 2000 [ 40%] (Warmup)
## Chain 3: Iteration: 1000 / 2000 [ 50%] (Warmup)
## Chain 3: Iteration: 1001 / 2000 [ 50%] (Sampling)
## Chain 3: Iteration: 1200 / 2000 [ 60%] (Sampling)
## Chain 3: Iteration: 1400 / 2000 [ 70%] (Sampling)
## Chain 3: Iteration: 1600 / 2000 [ 80%] (Sampling)
## Chain 3: Iteration: 1800 / 2000 [ 90%] (Sampling)
## Chain 3: Iteration: 2000 / 2000 [100%] (Sampling)
## Chain 3:
## Chain 3: Elapsed Time: 0.014 seconds (Warm-up)
## Chain 3: 0.013 seconds (Sampling)
## Chain 3: 0.027 seconds (Total)
## Chain 3:
##
## SAMPLING FOR MODEL 'continuous' NOW (CHAIN 4).
## Chain 4:
## Chain 4: Gradient evaluation took 4e-06 seconds
## Chain 4: 1000 transitions using 10 leapfrog steps per transition would take 0.04 seconds.
## Chain 4: Adjust your expectations accordingly!
## Chain 4:
## Chain 4:
## Chain 4: Iteration: 1 / 2000 [ 0%] (Warmup)
## Chain 4: Iteration: 200 / 2000 [ 10%] (Warmup)
## Chain 4: Iteration: 400 / 2000 [ 20%] (Warmup)
## Chain 4: Iteration: 600 / 2000 [ 30%] (Warmup)
## Chain 4: Iteration: 800 / 2000 [ 40%] (Warmup)
## Chain 4: Iteration: 1000 / 2000 [ 50%] (Warmup)
## Chain 4: Iteration: 1001 / 2000 [ 50%] (Sampling)
## Chain 4: Iteration: 1200 / 2000 [ 60%] (Sampling)
## Chain 4: Iteration: 1400 / 2000 [ 70%] (Sampling)
## Chain 4: Iteration: 1600 / 2000 [ 80%] (Sampling)
## Chain 4: Iteration: 1800 / 2000 [ 90%] (Sampling)
## Chain 4: Iteration: 2000 / 2000 [100%] (Sampling)
## Chain 4:
## Chain 4: Elapsed Time: 0.013 seconds (Warm-up)
## Chain 4: 0.014 seconds (Sampling)
## Chain 4: 0.027 seconds (Total)
## Chain 4: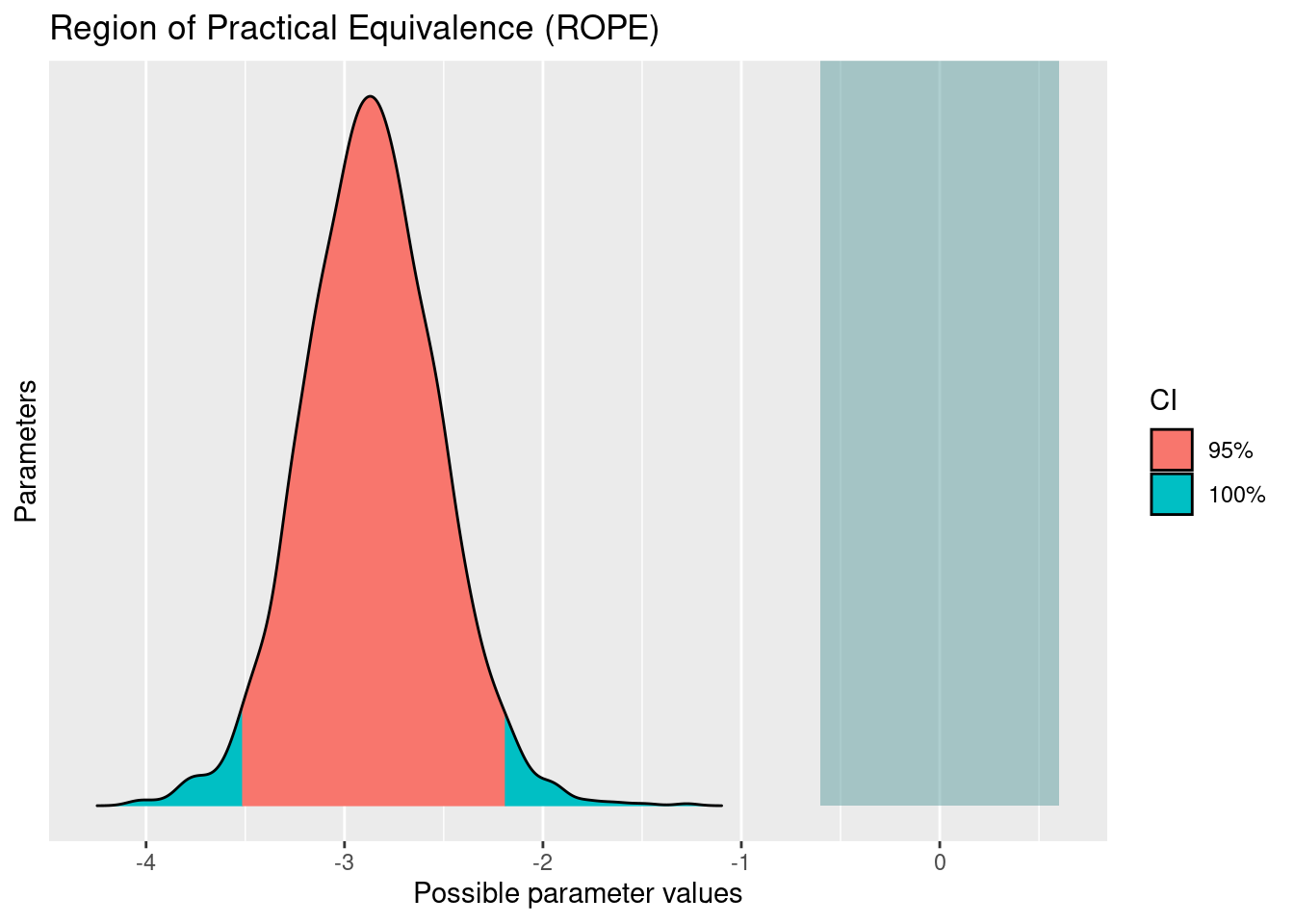
Wenn man die Null bzw. den Nullbereich (ROPE) eines Parameters ausschließt, nennt man das Ergebnis bzw. den Effekt auch “signifikant” (leider ein häufig missbrauchter und missverstandener Begriff). Unser Effekt in diesem Beispiel ist also signifikant (nach dieser Definition). Besser ist es aber, wenn Sie den Begriff vermeiden, und stattdessen davon sprechen, dass Sie einen Effekt gefunden haben (oder nicht oder dass eine unklare Ergebnislage vorliegt). Haben Sie einen Effekt gefunden, so heißt das synonym, dass die Nullhypothese ausgeschlossen ist (falsifiziert ist), natürlich immer auf Basis des vorliegenden Modells bzw. der vorliegenden Daten.
12.2.3.3 Modellgüte
Berechnen wir abschließend noch eine standardisierte Effektstärke der Modellgüte, \(R²\).
r2(m_bringtnixtin)
## # Bayesian R2 with Compatibility Interval
##
## Conditional R2: 0.088 (95% CI [2.061e-09, 0.252])Also etwa 9% erklärte Varianz. Aber ist das viel oder wenig? Fragen wir Herr Cohen, der hat sich dazu mal Gedanken gemacht.
interpret_r2(.09)
## [1] "weak"
## (Rules: cohen1988)Nach dieser Einschätzung ist der Effekt von g also schwach.
12.3 Vorher-Nachher-Messung, 1 between-Variable
12.3.1 Design
Sauer & Lustig (2023) fiel auf, dass es sinnvoller ist, zuerst die AV mittels eines Vortests zu messen, dann die Intervention anzuwenden, und dann nachher (Posttest) die AV wieder zu messen. Daher haben sie sowohl vor der Intervention (t1) als auch nach der Intervention (Gabe von Bringtnixtin), t2, die AV (y, Behaltensleistung) gemessen.
Eine Vorher-Nachher-Messung hat den Verteil, dass sie - im Gegensatz zur Nur-Nachher-Messung - unterschiedliche Ausgangswerte in der AV herausrechnet. Damit kommt man oft zu belastbareren, also besseren, Ergebnissen. Bei großen Gruppen wird sich bei einer randomisierten Zuweisung zu den Gruppen der Ausgangswert der AV angleichen. Bei nicht so großen Gruppen kann aber auch bei Randomisierung ein - mitunter erheblicher - Unterschied zwischen den Gruppen verbleiben. Findet man bei der Post-Messung einen Effekt, so kann es sein, dass dieser nicht auf die Intervention beruht, sondern auf die von vornherein vorhandenen Unterschieden zwischen den Gruppen.\(\square\)
Vergleicht man die Delta-Werte zwischen zwei Gruppen, berechnet man die Differenz zwischen den Gruppen der Delta-Werte. Man spricht daher von einer Difference-in-Difference-Analyse.\(\square\)
Abbildung 12.9 zeigt den Ablaufplan dieses Experiments.
flowchart LR Intro --> y1 y1 --> g.1 y1 --> g.2 g.1 --> y2 g.2 --> y2 y2 --> outro
DAG des Experiments ist in Abbildung 12.10 dargestellt.
12.3.2 Deskriptive Analyse
Eine einfache (und sinnvolle) Art, solche Studiendesigns auszuwerten ist die Bildung einer Differenz-Variable3. Diese Differenzvariable gibt die Veränderung der fluiden Intelligenz durch die Intervention an. Anders gesagt: Die Differenz ist die IQ-Wert einer Person nach der Intervention minus dem IQ-Wert vor der Intervention: \(d = y_2 - y_1\):
Schauen wir uns die ersten paar d-Werte für jede der beiden Gruppen (g=0 bzw. g=1) an:
| id | g | y1 | y2 | d |
|---|---|---|---|---|
| 1 | 0 | 1.37 | 1.41 | 0.04 |
| 2 | 0 | -0.56 | -0.64 | -0.07 |
| 3 | 0 | 0.36 | 0.51 | 0.15 |
| 21 | 1 | -0.31 | -0.71 | -0.41 |
| 22 | 1 | -1.78 | -2.08 | -0.30 |
| 23 | 1 | -0.17 | -0.39 | -0.22 |
Vielleicht ist es anschaulicher, wenn wir die Gruppe 0 in den Text Kontrollgruppe umbenennen und 1 in Experimentalgruppe:
Hier sind die Mittelwerte für jede der beiden Gruppen:
| g_text | d |
|---|---|
| Experimentalgruppe | -0.30 |
| Kontrollgruppe | -1.82e-04 |
Die deskriptiven Kennwerte sind in Abbildung 12.11 dargestellt.
ggbetweenstats(
data = d_bringtnixtin,
x = g_text,
y = d,
results.subtitle = FALSE # keine Statistiken zeigen
)
12.3.3 Modellierung und Inferenz
Wir modellieren (in m_bringtnixtin2) jetzt die Veränderung d = y2 - y1 als AV; UV ist wieder g, s. Tabelle 12.4.
m_bringtnixtin2 <- stan_glm(d ~ g,
data = d_bringtnixtin)
parameters(m_bringtnixtin2)m_bringtnixtin2
| Parameter | Median | 95% CI | pd | Rhat | ESS (tail) | Prior |
|---|---|---|---|---|---|---|
| (Intercept) | -2.64e-04 | (-0.08, 0.08) | 50.22% | 1.000 | 3010 | Normal (-0.15 +- 0.59) |
| g | -0.30 | (-0.42, -0.19) | 100% | 1.000 | 2242 | Normal (0.00 +- 1.17) |
Abbildung 12.12 zeigt die Parameterwerte für m_bringtnixtin2,

Wie man den Parameterwerten entnehmen kann, ist sich das Modell sehr sicher, dass der Effekt von Bringtnixtin negativ ist.
Testen wir noch die Praktisch-Null-Hypothese (für den Effekt von g auf d) mit dem ROPE-Verfahren:
rope(m_bringtnixtin2)Das Ergebnis zeigt uns, dass wir die Praktisch-Null-Hypothese ausschließen können: Null Prozent des 95%-HDI liegt im ROPE.
plot(rope(m_bringtnixtin2)) + scale_fill_okabeito()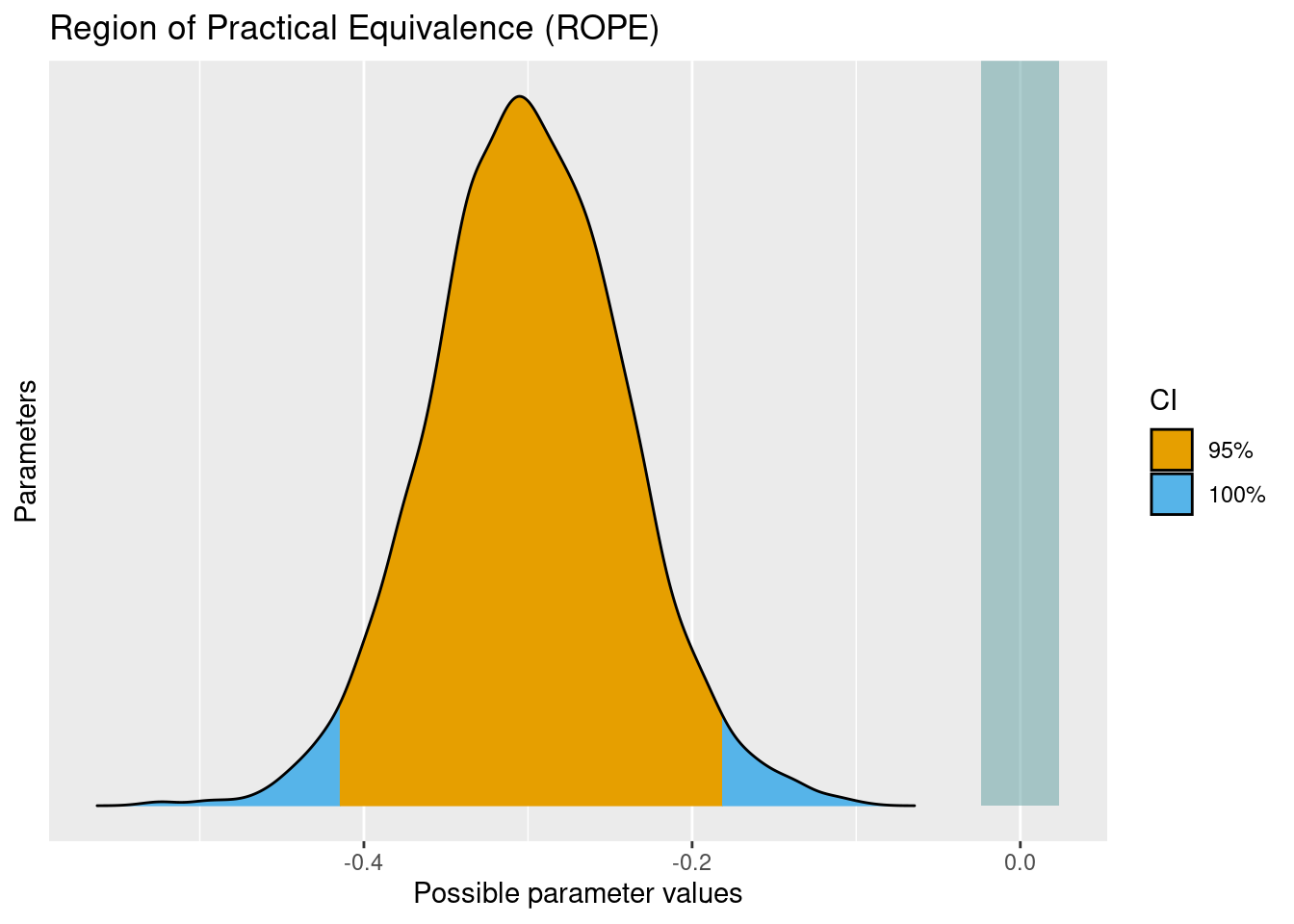
12.3.4 Fallstudie
Hier ist eine Fallstudie einer studentischen Arbeit vorgestellt, in der Einsamkeit experimentell induziert wird und dann der Effekt auf wahrgenommene Einsamkeit untersucht wird (unter anderem).
12.4 Beobachtungsstudien
Gängige Forschungsfragen für Beobachtungsstudien sind im Skript Start:Byes aufgeführt, schauen Sie mal [hier]https://start-bayes.netlify.app/1000-metrische-av).
12.5 1 within-Variable
Eine Studie mit Vorher-Nachher-Messung setzt ein Within-Design um.
Beispiel 12.2 (Statisches Diagramm vs. animiertes Diagramm) Ein Forschungsteam untersuch den Effekt der UV Visualisierungsart V (mit den zwei Stufen V.1 animiert und V.2 statisch) auf die Behaltensleistung (y) von Probanden. Nach jeder Bedingung wird die Behaltensleistung gemessen (anhand von 10 Wissensfragen, die jeweils als “richtig” oder “falsch” bewertet wurden), mit y1 nach V.1 und y2 für V.2.\(\square\)
12.5.1 Design
Forschungsfrage:
Hat die Diagrammart einen Einfluss auf die Behaltensleistung? Anders gesagt: Unterscheiden sich die Diagrammarten in ihrem Einfluss auf die mittlere Behaltensleistung?
Die zugehörige statistische Hypothese kann man so formulieren: \(\bar{d} \ne 0\), wobei \(d = y_1 - y_2\). \(d\) misst also den Unterschied der Behaltensleistung von animierten und statischen Diagrammen, wobei positive Werte zugunsten von statischen Diagrammen sprechen.
Die Modellformel lautet: d ~ 1, das ist ein Intercept-Modell, also ein Modell ohne Prädiktor. Uns interessiert, ob die Variable d im Mittelwert ungleich Null ist oder positiv (zugunsten statischer Diagramme) oder negativ (Behaltensleistung höher bei animierten Diagrammen).
Der Ablauf der Studie (aus Sicht der Probandis) ist in Abbildung 12.14 dargestellt.
flowchart LR V.1 --> y1 --> V.2 --> y2
Der DAG des Experiments ist in Abbildung 12.15 dargestellt.
12.5.2 Deskriptive Analyse
Hier sind einige Spieldaten:
Wir berechnen d, was die zentrale Variable der Forschungsfrage ist.
Es klingt trivial, aber man muss sich ein Bild von den Daten (hier d) machen, wortwörtlich, s. Abbildung 12.16.
gghistostats(d_within,
x = d,
results.subtitle = FALSE # verzichte auf zusätzliche Statistiken
)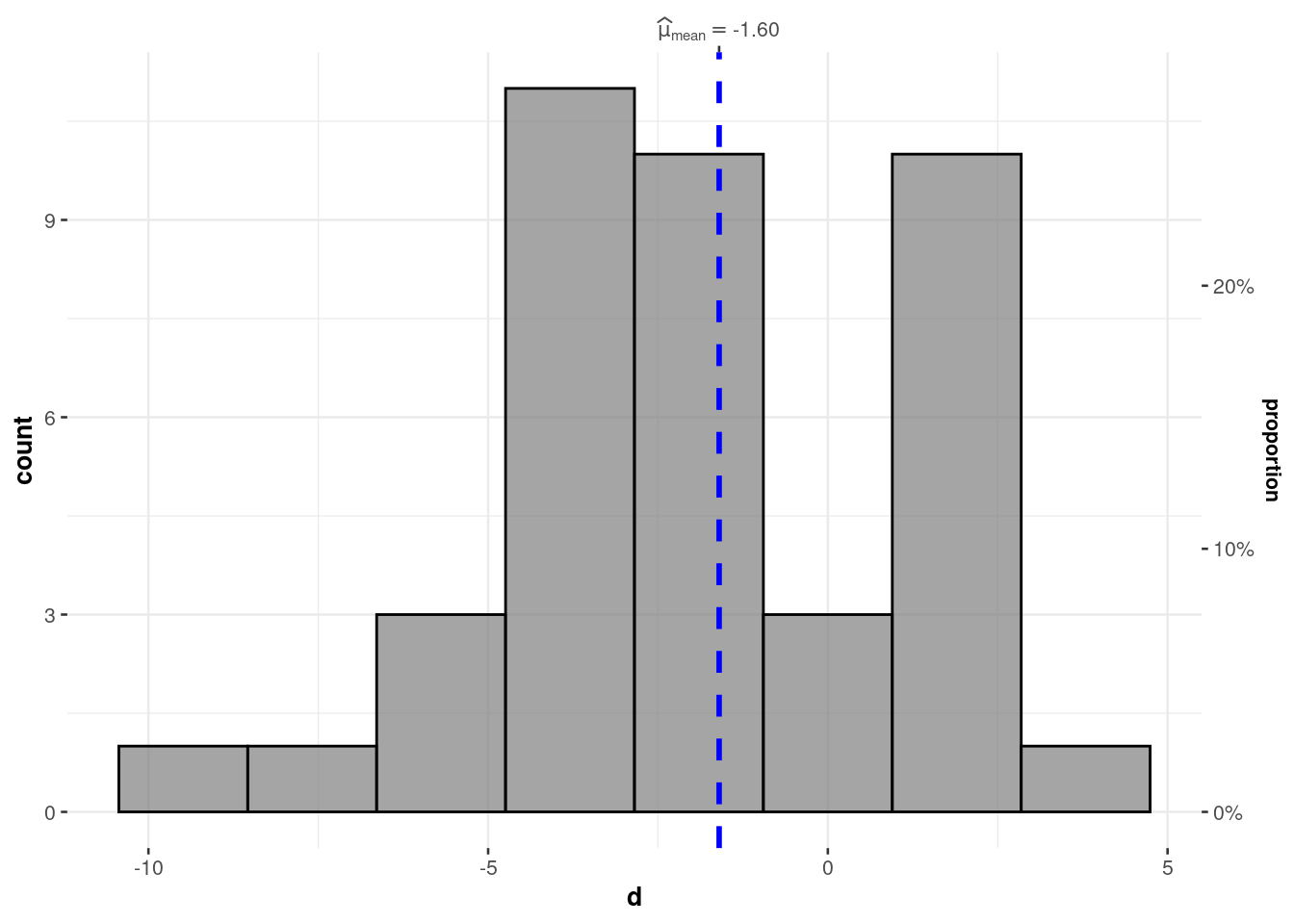
Da d im Mittel negativ ist, ist der Mittelwert von y2 (animiert) höher als der von y1 (statisch).
Lassen wir uns die deskriptiven Kennwerte ausgeben, s. Tabelle 12.5.
d_within %>%
describe_distribution(d)d
| Variable | Mean | SD | IQR | Range | Skewness | Kurtosis | n | n_Missing |
|---|---|---|---|---|---|---|---|---|
| d | -1.60 | 2.63 | 4 | (-9.00, 3.00) | -0.55 | 0.30 | 40 | 0 |
Um die Daten noch anders visualisieren zu können, formen wir sie ins “lange Format” um.
d_long <-
d_within %>%
pivot_longer(cols = c(y1, y2), names_to = "time", values_to = "y")Hier ist ein Auszug aus der Tabelle:
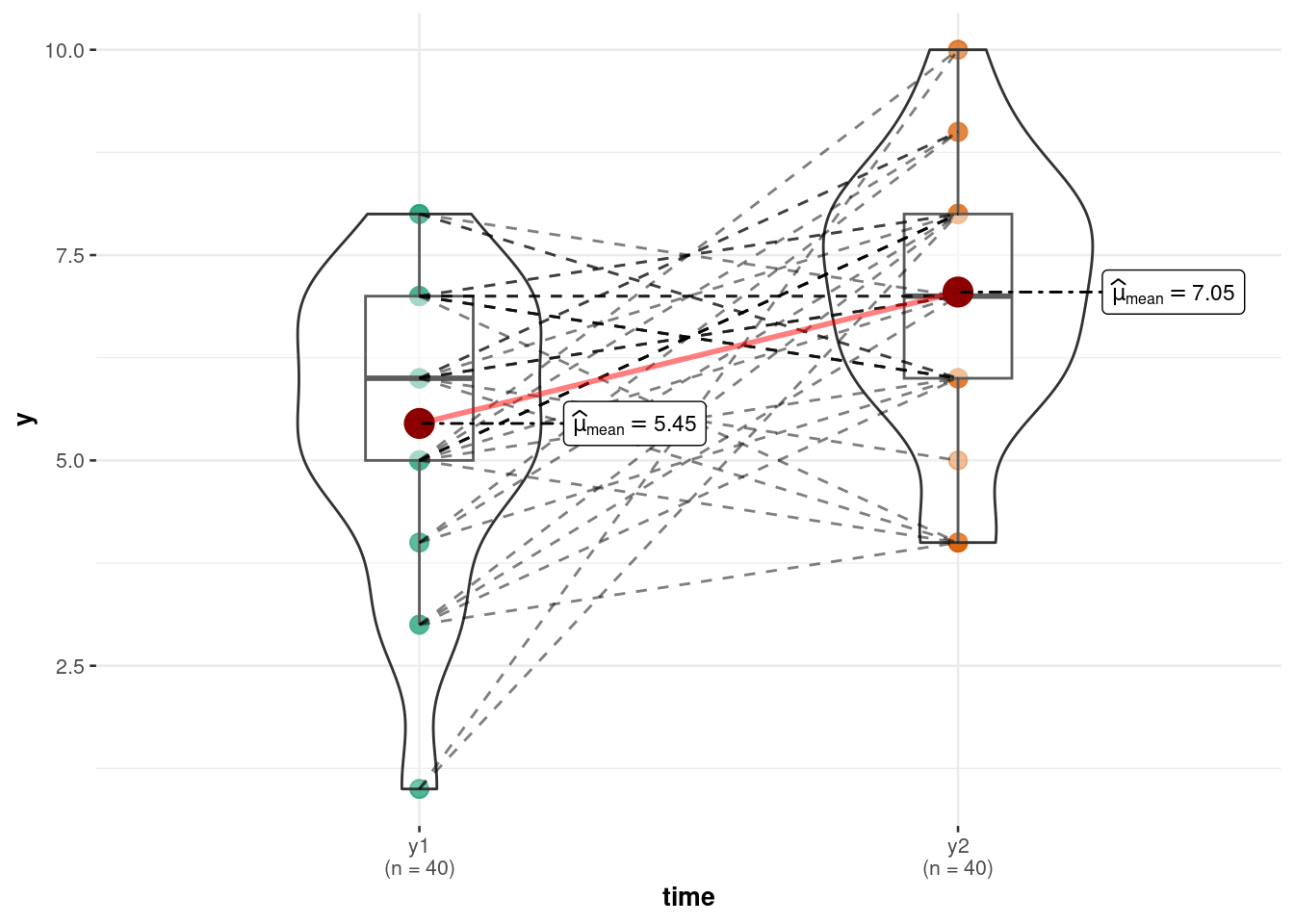
head(d_long)Visualisieren wir uns die Daten, s. Abbildung 12.17.
ggwithinstats(
data = d_long,
x = time,
y = y,
results.subtitle = FALSE # verzichte auf zusätzliche Statistiken
)
12.5.3 Modellierung und Inferenz
Wir berechnen das Modell (m_within), s. Tabelle 12.6:
m_within <- stan_glm(d ~ 1,
data = d_within)
parameters(m_within)| Parameter | Median | 95% CI | pd | Rhat | ESS (tail) | Prior |
|---|---|---|---|---|---|---|
| (Intercept) | -1.62 | (-2.46, -0.74) | 100% | 1.001 | 2055 | Normal (-1.60 +- 6.57) |
Hier ist eine Visualisierung des 95%-ETI des Unterschieds (d) zwischen den beiden Bedingungen (Abbildung 12.18).
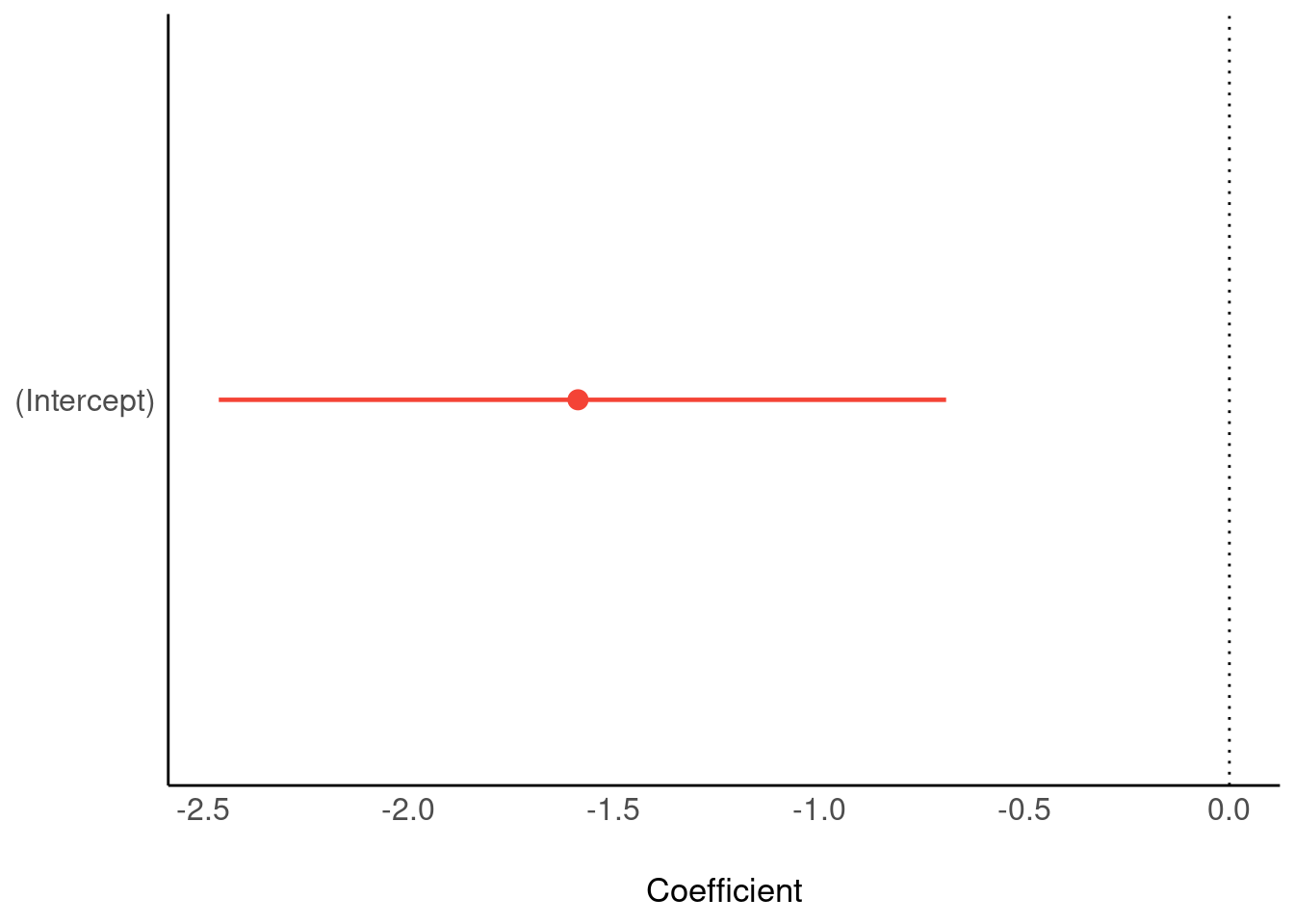
Wenn Sie die parameters plotten und nur einen Intercept haben, müssen Sie mit show_intercept=TRUE einschalten, dass er gezeigt wird. Sonst gibt es eine Fehlermeldung.\(\square\)
Wie man sieht, ist die Null nicht im CI enthalten. Wir können daher resümieren, dass es einen Unterschied zwischen den Bedingungen (statisch vs. animiert) gibt hinsichtlich y2 (Behaltensleistung). Die Behaltensleistung animierter Diagramme ist der von statischen Diagrammen überlegen (laut diesem Modell). Die exakte Nullhypothese ist zu verwerfen. Natürlich könnte man jetzt noch ein Rope berechnen.
12.5.4 Vertiefung
In diesem Blog-Post findet eine kleine Fallstudie zur Analyse von “Vorher-Nachher-Daten”.
12.6 1 within-Variable, 1 between-Variable
12.6.1 Design
Forschungsfrage:
Hat die Diagrammart einen Einfluss auf die Behaltensleistung? Anders gesagt: Unterscheiden sich die Diagrammarten in ihrem Einfluss auf die Behaltensleistung? Dabei kontrollieren wir die Reihenfolge.
Forschungspraktisch bedeutet das, dass es zwei (Between-)Gruppen, g1 und g2 in diesem Experiment gibt. Diese beiden Gruppen definieren eine Between-UV, G, die die Reihenfolge der Darbietung kontrolliert, s. Abbildung 12.19. Die Diagrammart V ist auch eine UV, aber als Within-UV konzipiert (mit den zwei Stufen V.1 und V.2).
flowchart LR
subgraph g2
direction LR
V.1 --> y1 --> V.2 --> y2
end
subgraph g1
direction LR
D2[V.2] --> y22[y2] --> D1[V.1] --> y11[y1]
end
Da es zwei UVs gibt, gibt es auch zwei Hypothesen:
- H1: \(\bar{d} < 0\), mit \(d = y_1 - y_2\): Die mittlere Behaltensleistung ist in der Bedingung animiert höher als in der Bedingung statisch.
- H2: \(\bar{d}_{g.1} = \bar{d}_{g.2}\): Der Unterschied in der Behaltensleistung zwischen den zwei Bedingung unterscheidet sich nicht von der Reihenfolge der Darbietung.
Die Modellformel lautet: y ~ 1 + g. Das kann man synonym so schreiben: y ~ g. Dabei meint y meint die Behaltensleistung; statistisch erfassen wir den Effekt auf y anhand des Differenzmaßes d.
Der DAG des Experiments ist in Abbildung 12.20 dargestellt.

12.6.2 Deskriptive Analyse
Hier sind einige Spieldaten:
Wir berechnen d, der Unterschied zwischen den beiden Bedingungen:
Betrachten wir den Unterschied von d zwischen den Gruppen (H2), s. Abbildung 12.21.
ggbetweenstats(
d_within,
x = g,
y = d,
results.subtitle = FALSE
)
Es gibt einen gewissen Unterschied zwischen den beiden Reihenfolgen (A und B) wie Abbildung 12.21 zeigt; die Reihenfolge könnte also einen Einfluss auf d haben. Aber wir müssen inferenzstatistisch prüfen, wie groß der Einfluss ist.
12.6.3 Inferenzanalyse
Berechnen wir m_within2, das nicht nur den Intercept prüft (wie m_within1), sondern auch zusätzlich den Effekt der Reihenfolge (g), vgl. Tabelle 12.7.
m_within2 <- stan_glm(d ~ g,
data = d_within)| Parameter | Median | 95% CI | pd | Rhat | ESS (tail) | Prior |
|---|---|---|---|---|---|---|
| (Intercept) | -1.13 | (-2.31, 0.04) | 97.15% | 1.000 | 2924 | Normal (-1.60 +- 6.57) |
| gB | -0.93 | (-2.56, 0.76) | 86.28% | 1.000 | 2176 | Normal (0.00 +- 12.98) |
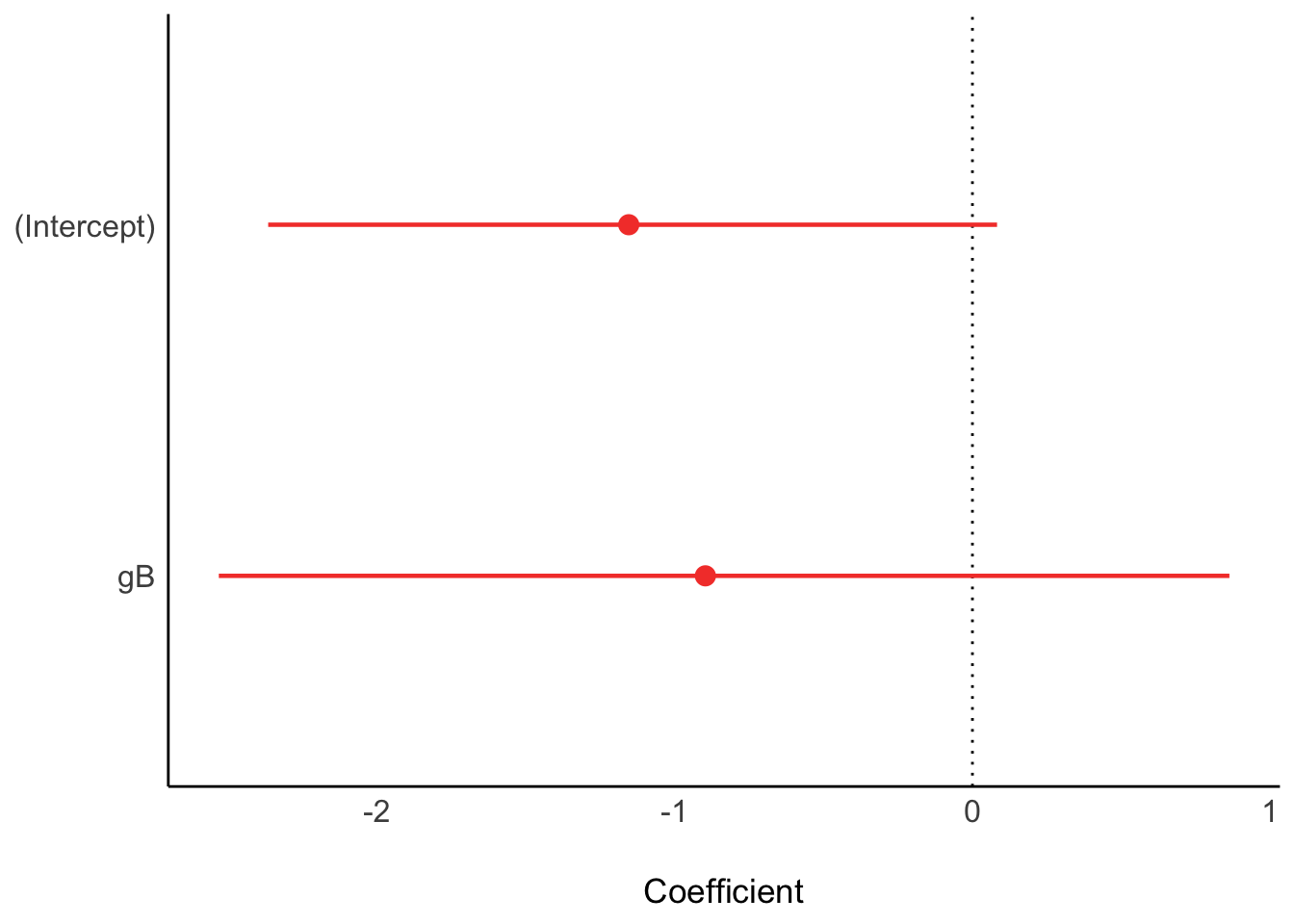
Das CI für die Reihenfolge (Variable gB) beinhaltet die Null; Daher kann ein Nulleffekt der Reihenfolge - also kein Effekt der Reihenfolge - nicht ausgeschlossen werden, g=0 ist also im Bereich der plausiblen Werte.
Der Effekt für d ((Intercept)) zeigt ein Intervall, das die Null (knapp) enthält. Daher können wir wir die Nullhypothese nicht mit hoher Sicherheit ausschließen.
In Summe:
- H1: (Höhere Behaltensleistung von animiert) konnte nicht bestätigt werden, aber tendenziell fand sich ein Effekt in erwarteter Richtung (zugunsten einer höheren Behaltensleistung von animiert).
- H2: (Abwesenheit eines Reihenfolgeeffekts) konnte nicht bestätigt werden; die Ergebnislage war uneindeutig.
12.7 Einfache Mediatoranalyse
12.7.1 Grundlagen
Die Mediatoranalyse fragt, wodurch wird ein Effekt von \(X\) auf \(Y\) übertragen (s. Abbildung 12.23)? Das ist eine Stufe komplexer, als zu fragen, ob \(X\) einen Effekt auf \(Y\) hat (s. Abbildung 12.22).
Ein Mediatormodell besteht also aus drei Variablen:
-
X- UV -
Y- AV -
M- Mediator
Ein Mediatormodell besteht auch aus vier Pfaden bzw. Effekten, s. Abbildung 12.23:
- Pfad a: \(X \rightarrow M\) - Der Effekt der UV auf den Mediator
- Pfad b: \(M \rightarrow Y\) - Der Effekt des Mediators auf die AV
- Pfad c’: \(X \rightarrow Y\) - Der “direkte” Effekt der UV auf die AV (unter Kontrolle (“Ausschluss”) des Mediators)
- Pfad ab: \(X \rightarrow Y\) - Der “indirekte” Effekt der UV auf die AV über den Mediator
graph LR X --> Y
graph LR X -->|a| M X -->|c'| Y M -->|b| Y
12.7.2 Fallbeispiel
Verringert ein Jobtraining (eine Intervention der Arbeitsagentur; treat als \(X\)) die Depressivität (depress2 als \(Y\)) von Jobsuchenden vermittelt durch den Mediator Selbstwirksamkeit (job_seek als \(M\)), s. Abbildung 12.24? Die Daten sind dem Datensatz jobs entnommen.
library(mediation)
data(jobs)
glimpse(jobs)
## Rows: 899
## Columns: 17
## $ treat <int> 1, 1, 1, 0, 1, 1, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, …
## $ econ_hard <dbl> 3.00, 3.67, 4.00, 2.33, 1.33, 3.00, 3.33, 4.00, 1.33, 3.00, …
## $ depress1 <dbl> 1.91, 1.36, 2.09, 1.45, 1.73, 1.55, 2.45, 2.73, 1.27, 1.64, …
## $ sex <int> 1, 0, 1, 0, 1, 0, 1, 1, 1, 0, 0, 1, 1, 0, 1, 0, 1, 1, 1, 1, …
## $ age <dbl> 34.16712, 26.10137, 35.02192, 27.48767, 31.61096, 40.43835, …
## $ occp <fct> professionals, operatives/kindred wrks, operatives/kindred w…
## $ marital <fct> married, nevmarr, nevmarr, married, separtd, married, marrie…
## $ nonwhite <fct> non.white1, white0, non.white1, white0, non.white1, white0, …
## $ educ <fct> gradwk, somcol, somcol, bach, highsc, highsc, gradwk, somcol…
## $ income <fct> 50k+, 15t24k, 25t39k, 25t39k, 25t39k, 50k+, 50k+, 15t24k, 15…
## $ job_seek <dbl> 4.833333, 3.833333, 4.500000, 3.666667, 2.500000, 4.000000, …
## $ depress2 <dbl> 1.727273, 2.000000, 2.181818, 1.545455, 2.363636, 1.181818, …
## $ work1 <fct> psyemp, psyemp, psyump, psyump, psyump, psyump, psyump, psyu…
## $ comply <int> 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 1, 0, 0, 0, …
## $ control <fct> treat, treat, treat, control, treat, treat, control, control…
## $ job_dich <dbl> 1, 0, 1, 0, 0, 1, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1, 1, 1, 1, 0, …
## $ job_disc <dbl> 4, 3, 4, 3, 2, 3, 3, 3, 3, 2, 4, 3, 1, 3, 3, 3, 3, 3, 4, 2, …\(\square\)
graph LR treat --> job_seek job_seek --> depress2 treat --> depress2
12.7.2.1 Mit mediation: Frequentistische Mediationsmodelle
Wir definieren zwei Regressionsmodelle:
- Das
m_model: \(X \rightarrow M\) - Das
y_model: \(X + M \rightarrow Y\)
m_model2 <- lm(job_seek ~ treat, data = jobs)
y_model2 <- lm(depress2 ~ treat + job_seek, data = jobs)
med_depress_freq <-
mediate(model.m = m_model2,
model.y = y_model2,
treat = "treat", # UV, X
mediator = "job_seek", # M
boot = TRUE, # Simulationstechniken nutzen
sims = 1000) # Anzahl der Simulationsdurchläufesummary(med_depress_freq)
##
## Causal Mediation Analysis
##
## Nonparametric Bootstrap Confidence Intervals with the Percentile Method
##
## Estimate 95% CI Lower 95% CI Upper p-value
## ACME -0.015198 -0.038074 0.006481 0.142
## ADE -0.048148 -0.133162 0.036850 0.294
## Total Effect -0.063346 -0.150559 0.029981 0.178
## Prop. Mediated 0.239922 -1.289552 1.810372 0.236
##
## Sample Size Used: 899
##
##
## Simulations: 1000- ACME (Average Causal Mediation Effect): der indirekte Effekt
- ADE (Average Direct Effect): Der direkte Effekt
- Total Effect: Die Summe von indirektem und direktem Effekt
- Prop. Mediated: Der Anteil des indirekten Effekt (ACME) am Gesamteffekt (Total Effect)
Wie man sieht, ist im ACME die Null enthalten. Wir können also einen Nulleffekt nicht ausschließen.
12.7.2.2 Mit bmlm: Bayes Multilevel Mediation
Achtung: Die Funktion mlm kann mehrere Minuten zum Durchlaufen benötigen.
med_depress_mlm <-mlm(
d = jobs,
id = "id",
x = "treat",
m = "job_seek",
y = "depress2",
iter = 2000,
chains = 1)mlm_path_plot(med_depress_mlm,
xlab = "Treat", mlab = "job_seek", ylab = "depress2",
text = TRUE)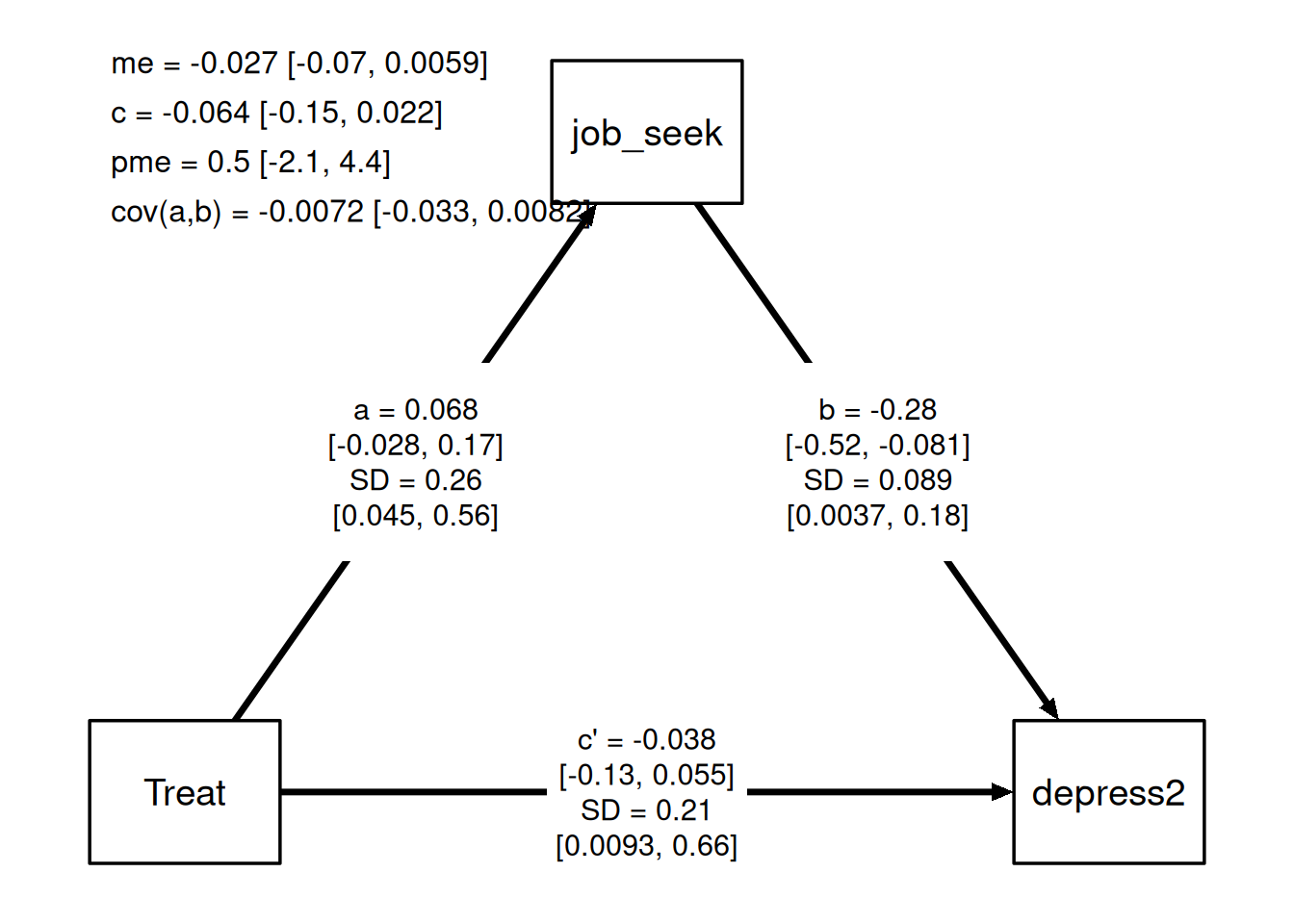
Hier sind die Erebnisse des Modells. Im Mediationseffket (me) ist die Null enthalten; daher ist die Nullhypothese nicht zu verwerfen.
mlm_summary(med_depress_mlm)-
a: Pfad a -
b: Pfad b -
cp: Pfad c’ (“c prime”) -
me: Medationseffekt (indirekter Effekt) -
c: Pfad c (totaler Effekt) -
pme: Anteil indirekter Effekt am Gesamteffekt (“proportion mediated effect”)
mlm_pars_plot(med_depress_mlm, pars = "me")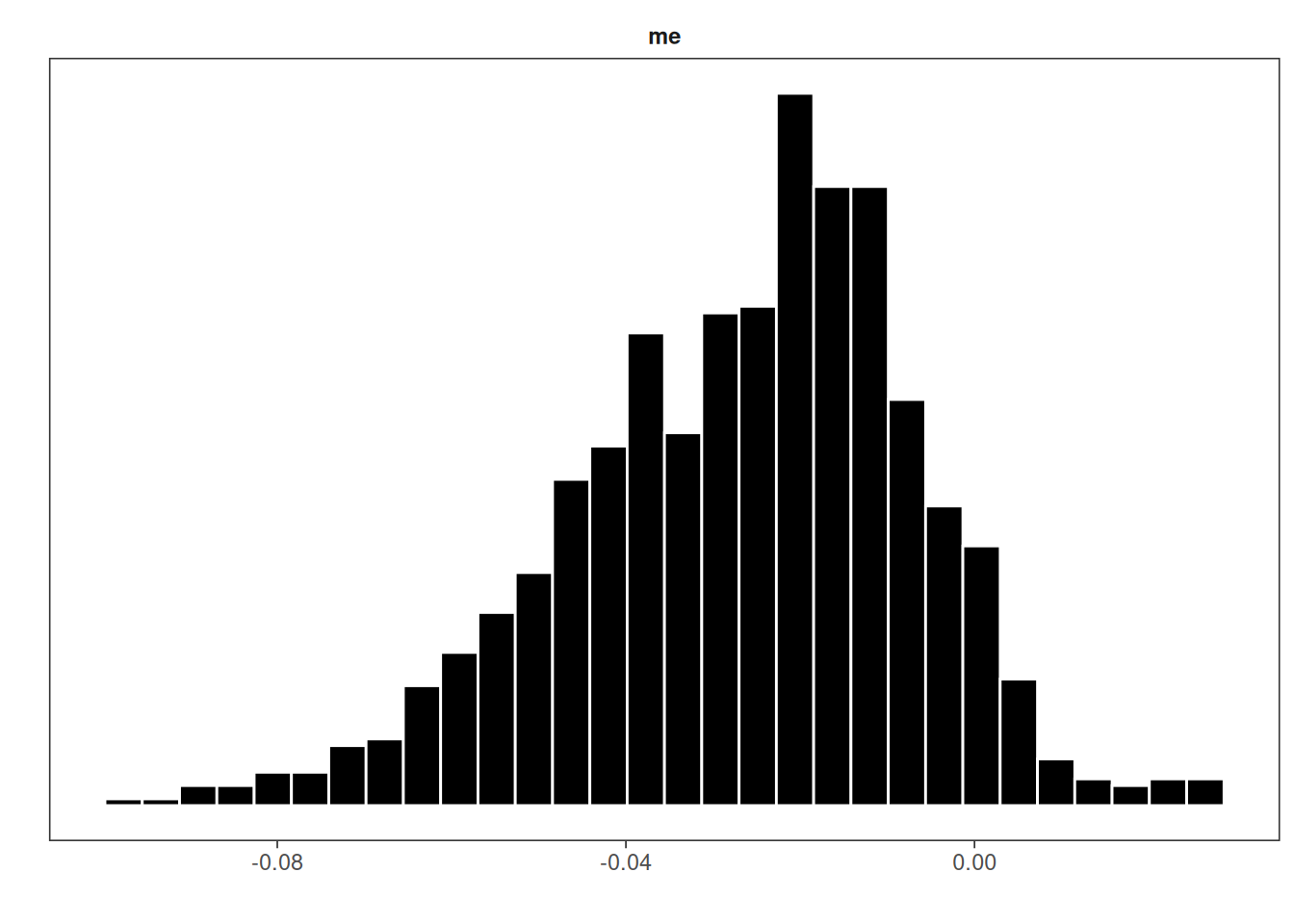
12.7.2.3 Mit brms: Bayes Regression modelling using Stan
m_model <- bf(job_seek ~ treat )
y_model <- bf(depress2 ~ treat + job_seek)
med_depress_brms <-
brm(
m_model + y_model + set_rescor(FALSE),
data = jobs
)
##
## SAMPLING FOR MODEL 'anon_model' NOW (CHAIN 1).
## Chain 1:
## Chain 1: Gradient evaluation took 1e-05 seconds
## Chain 1: 1000 transitions using 10 leapfrog steps per transition would take 0.1 seconds.
## Chain 1: Adjust your expectations accordingly!
## Chain 1:
## Chain 1:
## Chain 1: Iteration: 1 / 2000 [ 0%] (Warmup)
## Chain 1: Iteration: 200 / 2000 [ 10%] (Warmup)
## Chain 1: Iteration: 400 / 2000 [ 20%] (Warmup)
## Chain 1: Iteration: 600 / 2000 [ 30%] (Warmup)
## Chain 1: Iteration: 800 / 2000 [ 40%] (Warmup)
## Chain 1: Iteration: 1000 / 2000 [ 50%] (Warmup)
## Chain 1: Iteration: 1001 / 2000 [ 50%] (Sampling)
## Chain 1: Iteration: 1200 / 2000 [ 60%] (Sampling)
## Chain 1: Iteration: 1400 / 2000 [ 70%] (Sampling)
## Chain 1: Iteration: 1600 / 2000 [ 80%] (Sampling)
## Chain 1: Iteration: 1800 / 2000 [ 90%] (Sampling)
## Chain 1: Iteration: 2000 / 2000 [100%] (Sampling)
## Chain 1:
## Chain 1: Elapsed Time: 0.024 seconds (Warm-up)
## Chain 1: 0.024 seconds (Sampling)
## Chain 1: 0.048 seconds (Total)
## Chain 1:
##
## SAMPLING FOR MODEL 'anon_model' NOW (CHAIN 2).
## Chain 2:
## Chain 2: Gradient evaluation took 4e-06 seconds
## Chain 2: 1000 transitions using 10 leapfrog steps per transition would take 0.04 seconds.
## Chain 2: Adjust your expectations accordingly!
## Chain 2:
## Chain 2:
## Chain 2: Iteration: 1 / 2000 [ 0%] (Warmup)
## Chain 2: Iteration: 200 / 2000 [ 10%] (Warmup)
## Chain 2: Iteration: 400 / 2000 [ 20%] (Warmup)
## Chain 2: Iteration: 600 / 2000 [ 30%] (Warmup)
## Chain 2: Iteration: 800 / 2000 [ 40%] (Warmup)
## Chain 2: Iteration: 1000 / 2000 [ 50%] (Warmup)
## Chain 2: Iteration: 1001 / 2000 [ 50%] (Sampling)
## Chain 2: Iteration: 1200 / 2000 [ 60%] (Sampling)
## Chain 2: Iteration: 1400 / 2000 [ 70%] (Sampling)
## Chain 2: Iteration: 1600 / 2000 [ 80%] (Sampling)
## Chain 2: Iteration: 1800 / 2000 [ 90%] (Sampling)
## Chain 2: Iteration: 2000 / 2000 [100%] (Sampling)
## Chain 2:
## Chain 2: Elapsed Time: 0.024 seconds (Warm-up)
## Chain 2: 0.025 seconds (Sampling)
## Chain 2: 0.049 seconds (Total)
## Chain 2:
##
## SAMPLING FOR MODEL 'anon_model' NOW (CHAIN 3).
## Chain 3:
## Chain 3: Gradient evaluation took 4e-06 seconds
## Chain 3: 1000 transitions using 10 leapfrog steps per transition would take 0.04 seconds.
## Chain 3: Adjust your expectations accordingly!
## Chain 3:
## Chain 3:
## Chain 3: Iteration: 1 / 2000 [ 0%] (Warmup)
## Chain 3: Iteration: 200 / 2000 [ 10%] (Warmup)
## Chain 3: Iteration: 400 / 2000 [ 20%] (Warmup)
## Chain 3: Iteration: 600 / 2000 [ 30%] (Warmup)
## Chain 3: Iteration: 800 / 2000 [ 40%] (Warmup)
## Chain 3: Iteration: 1000 / 2000 [ 50%] (Warmup)
## Chain 3: Iteration: 1001 / 2000 [ 50%] (Sampling)
## Chain 3: Iteration: 1200 / 2000 [ 60%] (Sampling)
## Chain 3: Iteration: 1400 / 2000 [ 70%] (Sampling)
## Chain 3: Iteration: 1600 / 2000 [ 80%] (Sampling)
## Chain 3: Iteration: 1800 / 2000 [ 90%] (Sampling)
## Chain 3: Iteration: 2000 / 2000 [100%] (Sampling)
## Chain 3:
## Chain 3: Elapsed Time: 0.023 seconds (Warm-up)
## Chain 3: 0.024 seconds (Sampling)
## Chain 3: 0.047 seconds (Total)
## Chain 3:
##
## SAMPLING FOR MODEL 'anon_model' NOW (CHAIN 4).
## Chain 4:
## Chain 4: Gradient evaluation took 4e-06 seconds
## Chain 4: 1000 transitions using 10 leapfrog steps per transition would take 0.04 seconds.
## Chain 4: Adjust your expectations accordingly!
## Chain 4:
## Chain 4:
## Chain 4: Iteration: 1 / 2000 [ 0%] (Warmup)
## Chain 4: Iteration: 200 / 2000 [ 10%] (Warmup)
## Chain 4: Iteration: 400 / 2000 [ 20%] (Warmup)
## Chain 4: Iteration: 600 / 2000 [ 30%] (Warmup)
## Chain 4: Iteration: 800 / 2000 [ 40%] (Warmup)
## Chain 4: Iteration: 1000 / 2000 [ 50%] (Warmup)
## Chain 4: Iteration: 1001 / 2000 [ 50%] (Sampling)
## Chain 4: Iteration: 1200 / 2000 [ 60%] (Sampling)
## Chain 4: Iteration: 1400 / 2000 [ 70%] (Sampling)
## Chain 4: Iteration: 1600 / 2000 [ 80%] (Sampling)
## Chain 4: Iteration: 1800 / 2000 [ 90%] (Sampling)
## Chain 4: Iteration: 2000 / 2000 [100%] (Sampling)
## Chain 4:
## Chain 4: Elapsed Time: 0.023 seconds (Warm-up)
## Chain 4: 0.026 seconds (Sampling)
## Chain 4: 0.049 seconds (Total)
## Chain 4:set_rescor(FALSE) setzt die Korrelation der Residuen von M und Y auf Null: Es sollte keinen Zusammenhang zwischen M und Y geben, der nicht durch X erklärt wird. Anders gesagt: Wir schließen Konfundierung durch unbeobachtete Variablen aus.
Ergebnisse:
summary(med_depress_brms)
## Family: MV(gaussian, gaussian)
## Links: mu = identity
## mu = identity
## Formula: job_seek ~ treat
## depress2 ~ treat + job_seek
## Data: jobs (Number of observations: 899)
## Draws: 4 chains, each with iter = 2000; warmup = 1000; thin = 1;
## total post-warmup draws = 4000
##
## Regression Coefficients:
## Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
## jobseek_Intercept 4.00 0.04 3.92 4.08 1.00 6109 3199
## depress2_Intercept 2.68 0.12 2.44 2.93 1.00 7016 3032
## jobseek_treat 0.07 0.05 -0.03 0.17 1.00 5966 3363
## depress2_treat -0.05 0.05 -0.14 0.04 1.00 7332 3325
## depress2_job_seek -0.23 0.03 -0.28 -0.17 1.00 7333 3240
##
## Further Distributional Parameters:
## Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
## sigma_jobseek 0.73 0.02 0.70 0.76 1.00 6600 2961
## sigma_depress2 0.63 0.02 0.60 0.66 1.00 6484 2839
##
## Draws were sampled using sampling(NUTS). For each parameter, Bulk_ESS
## and Tail_ESS are effective sample size measures, and Rhat is the potential
## scale reduction factor on split chains (at convergence, Rhat = 1).Den indirekten Effekt muss man sich selber berechnen:
post <- as_draws_df(med_depress_brms)
a <- post$b_jobseek_treat
b <- post$b_depress2_job_seek
post$indirect <- a * bDann kann man sich z. B. ein Konfidenzintervall ausgeben lassen:
hdi(post$indirect)hdi(post$indirect) |> plot()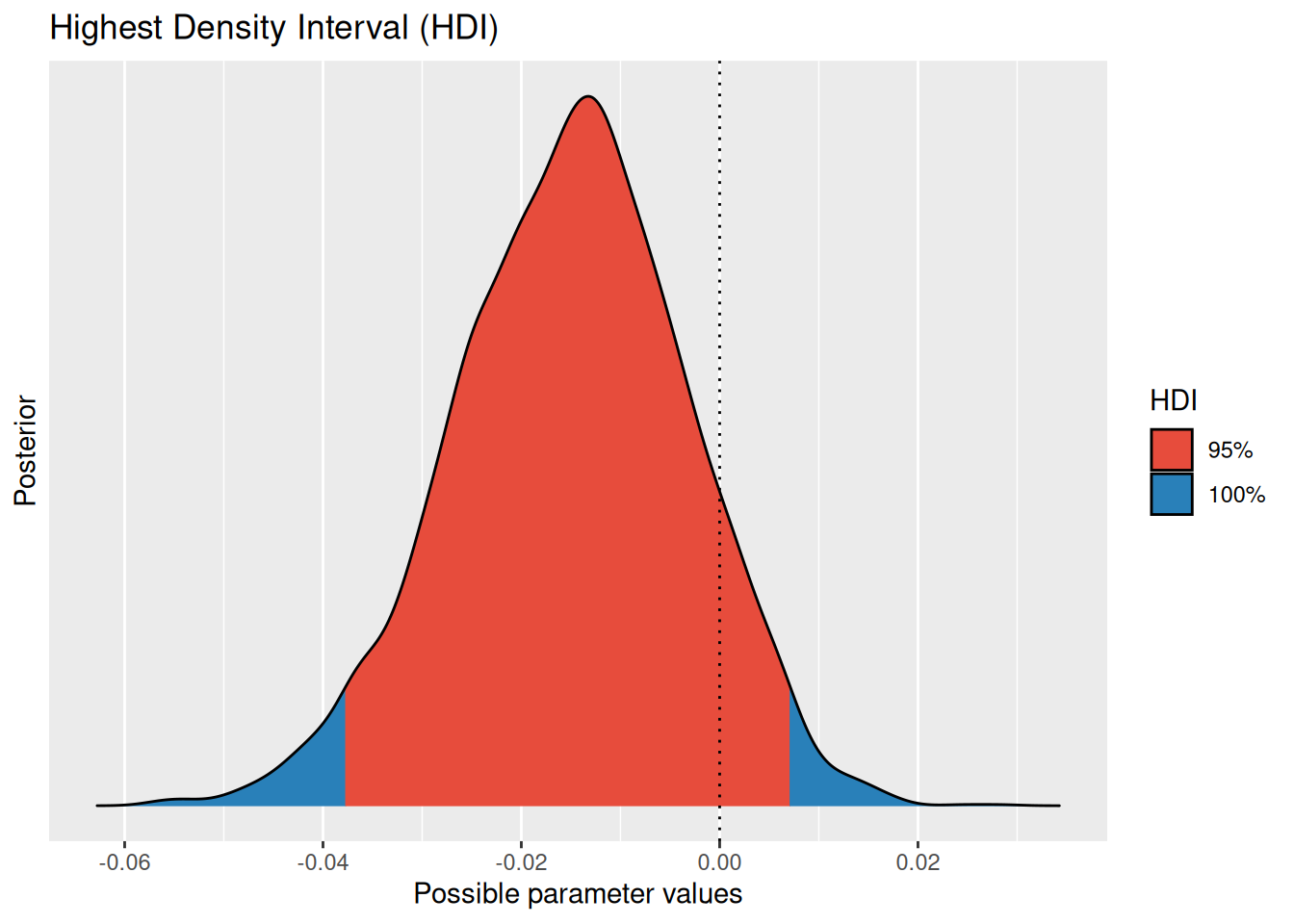
Wie man sieht, ist die Null im Intervall enthalten.
12.7.3 Vertiefung
Hier findet sich eine Einführung in die Mediationsanalyse. Dieses R-Paket stellt ebenfalls komfortable Funktionen zur Verfügung für Mediationsanalysen. Mit den “klickbaren” Programmen Jamovi oder JASP kann man ebenfalls - und zwar sehr einfach - eine Mediationsanalyse durchführen. Einfach mal ausprobieren!
12.8 Moderierte Mediation
Bei einer einfachen Mediation wirkt ein Prädiktor \(X\) über einen Mediator \(M\) auf ein Ergebnis \(Y\). Der indirekte Effekt ist das Produkt \(a \cdot b\) der beiden beteiligten Pfade. Eine moderierte Mediation liegt vor, wenn dieser indirekte Effekt selbst von einer weiteren Variable, dem Moderator \(W\), abhängt. Anders gesagt: Der Mechanismus, über den \(X\) auf \(Y\) wirkt, ist nicht für alle gleich stark.
Die zentrale Frage ist immer: Welcher Pfad wird moderiert? Diese Entscheidung ist theoretischer, nicht technischer Natur. Drei Leitfragen helfen:
- Hängt die Entstehung des Mediators von \(W\) ab? → a-Pfad
- Hängt die Übersetzung des Mediators in \(Y\) von \(W\) ab? → b-Pfad
- Hängt der direkte Resteffekt von \(X\) auf \(Y\) von \(W\) ab? → c′-Pfad
Die ersten beiden Fälle sind moderierte Mediation im engeren Sinn. Der dritte Fall moderiert den direkten Pfad und ist damit eine moderierte direkte Wirkung — dazu unten mehr.
12.8.1 Konzeptuelles und statistisches Diagramm
In der konzeptuellen Notation nach Hayes (2022) zeigt der Moderator mit einem Pfeil auf einen Pfad (nicht auf einen Knoten). Diese Darstellung macht die Hypothese unmittelbar lesbar, lässt sich aber nicht in jedem Diagramm-Werkzeug umsetzen.
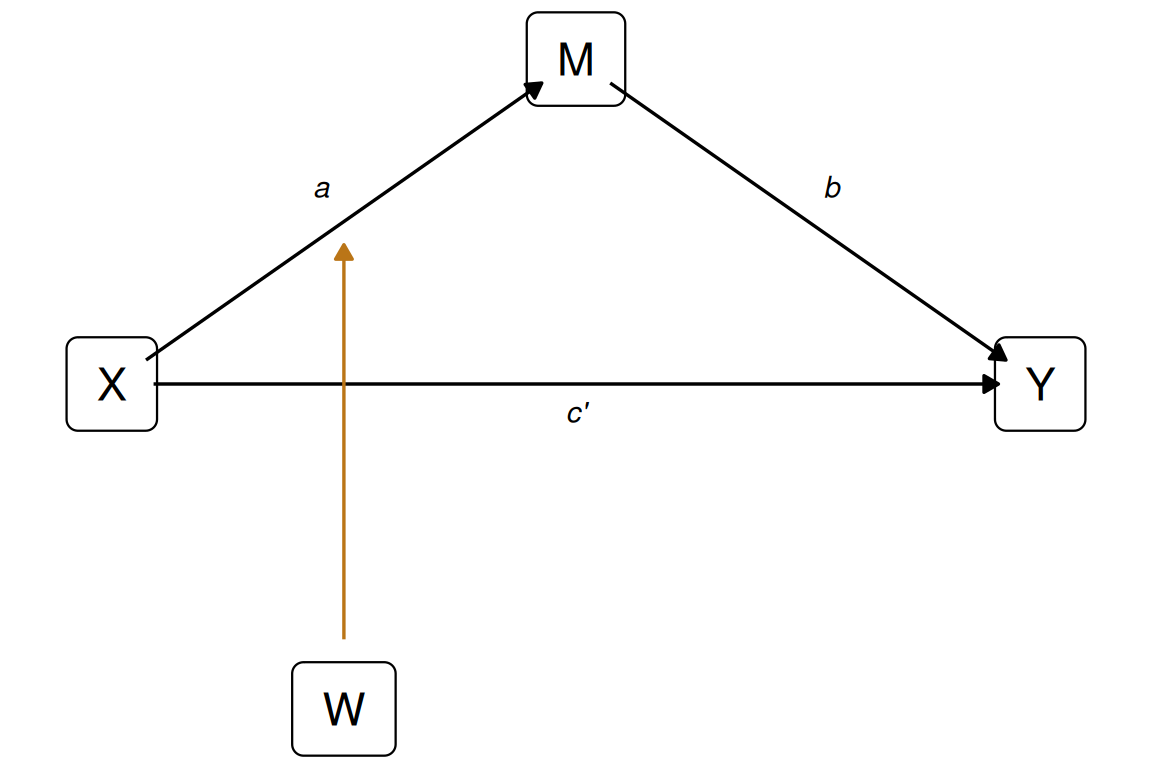
Im statistischen Diagramm wird die Moderation als Interaktionsterm \(X \cdot W\) aufgelöst, der als eigener Prädiktor auf \(M\) wirkt. Genau das schätzt das Regressionsmodell lm(M ~ X * W). Der Koeffizient dieses Interaktionsterms heißt \(a_3\).
12.8.2 Der Index der moderierten Mediation
Hayes (2015) führt den Index of moderated mediation ein. Wird der a-Pfad moderiert, ist der bedingte indirekte Effekt
\[ \text{indirekt}(W) = (a_1 + a_3 \cdot W) \cdot b , \]
und der Index ist schlicht
\[ \text{Index} = a_3 \cdot b . \]
Ist der Index von null verschieden (das Bootstrap-Konfidenzintervall schließt die Null aus), liegt moderierte Mediation vor. Der Test ist also ein Konfidenzintervall auf das Produkt \(a_3 \cdot b\).
12.8.3 Beispiel mit simulierten Daten
Wir erzeugen einen Datensatz, in dem der a-Pfad bewusst moderiert ist (der Term 0.5 * X * W):
12.8.3.1 Schätzung mit lavaan
Der Vorteil: Das Pfadmodell steht explizit im Code, nichts ist Blackbox. Der Interaktionsterm wird vorab gebildet:
library(lavaan)
d$XW <- d$X * d$W
modell <- '
# a-Pfad mit Interaktion X:W
M ~ a1*X + a2*W + a3*XW
# b-Pfad und direkter Pfad
Y ~ b*M + cp*X
# bedingte indirekte Effekte bei W = -1, 0, +1
ind_lo := (a1 + a3 * -1) * b
ind_mean := (a1 + a3 * 0) * b
ind_hi := (a1 + a3 * 1) * b
# Index der moderierten Mediation
index := a3 * b
'
fit <- sem(modell, data = d, se = "bootstrap", bootstrap = 1000)parameterEstimates(fit, ci = TRUE) |>
subset(label %in% c("ind_lo", "ind_mean", "ind_hi", "index"),
select = c(label, est, ci.lower, ci.upper))Der Parameter index ist der Kern: Schließt sein Konfidenzintervall die Null aus, ist die Mediation moderiert. Die drei ind_*-Werte zeigen, wie stark der indirekte Effekt bei niedrigem, mittlerem und hohem \(W\) ausfällt.
12.8.3.2 Bedingte indirekte Effekte über den Wertebereich von \(W\)
Statt nur dreier Stützstellen lässt sich der bedingte indirekte Effekt \((a_1 + a_3 W)\, b\) als stetige Funktion von \(W\) darstellen. Das macht unmittelbar sichtbar, wo der Mediationsmechanismus stark ist und wo er verschwindet:
est <- coef(fit)
a1 <- est["a1"]; a3 <- est["a3"]; b <- est["b"]
w_seq <- seq(min(d$W), max(d$W), length.out = 100)
plot_df <- data.frame(
W = w_seq,
effekt = (a1 + a3 * w_seq) * b
)
ggplot(plot_df, aes(x = W, y = effekt)) +
geom_hline(yintercept = 0, linetype = "dashed", colour = "grey50") +
geom_line(linewidth = 0.8, colour = "#185FA5") +
labs(x = "Moderator W",
y = "Bedingter indirekter Effekt") +
theme_minimal(base_size = 12)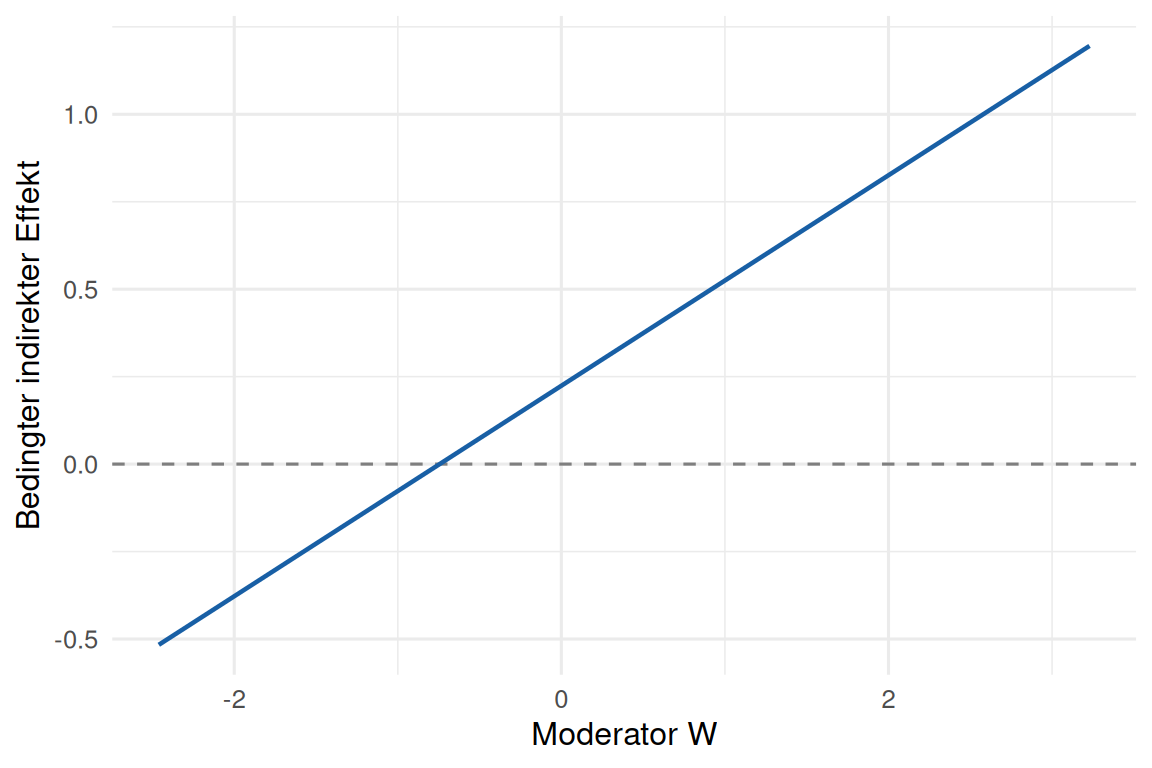
Ist die Gerade waagerecht (\(a_3 = 0\)), hängt der indirekte Effekt nicht von \(W\) ab — keine moderierte Mediation. Je steiler sie verläuft, desto stärker die Moderation. Genau diese Steigung ist der Index aus Hayes (2015).
12.8.3.3 Schätzung mit dem Paket mediation
Klassischer Weg über zwei getrennte Modelle:
library(mediation)
m_mod <- lm(M ~ X * W, data = d)
y_mod <- lm(Y ~ M + X, data = d)
# bedingte Mediation bei festem W
med_lo <- mediate(m_mod, y_mod, treat = "X", mediator = "M",
covariates = list(W = -1), boot = TRUE, sims = 1000)
med_hi <- mediate(m_mod, y_mod, treat = "X", mediator = "M",
covariates = list(W = 1), boot = TRUE, sims = 1000)
# Test, ob sich indirekte Effekte über W unterscheiden
test.modmed(med_lo,
covariates.1 = list(W = -1),
covariates.2 = list(W = 1),
sims = 1000)12.8.4 Sonderfall: Moderation des c′-Pfads
Wird nicht der a- oder b-Pfad, sondern der direkte Pfad c′ moderiert, ändert sich der indirekte Effekt nicht über \(W\) — nur der direkte Resteffekt von \(X\) auf \(Y\). Das ist inhaltlich eine andere Aussage: Der Mediationsmechanismus ist überall gleich stark, aber der direkte Effekt hängt von \(W\) ab.
Wichtig: Der Index of moderated mediation nach Hayes ist hier nicht definiert, weil der indirekte Effekt konstant bleibt. Getestet wird stattdessen der Interaktionskoeffizient \(X \cdot W\) in der \(Y\)-Gleichung.
modell_c <- '
M ~ a*X
Y ~ b*M + cp1*X + cp2*W + cp3*XW
indirect := a * b # konstant, nicht moderiert
# kein Index of moderated mediation
# stattdessen: ist cp3 signifikant?
'Der Begriff lautet dann korrekt moderierte direkte Wirkung, nicht moderierte Mediation.
12.9 Vertiefung
12.9.1 1 within-Variable mit mehr als zwei Stufen
VERTIEFUNG - Sie können diesen Abschnitt ohne Gefahr ignorieren.
12.9.2 Design
Eine Forscherin hat die Gesundheit (y) von Studentis drei Mal (t1, t2, t3) im Zeitraum eines Semesters untersucht.
Ihre Forschungsfrage lautet, ob sich die Gesundheit im Laufe des Semesters substanziell verändert. Ihre Hypothese lautet, dass die Werte über die Zeit hinweg stabil bleiben.
12.9.3 Deskriptive Analyse
Hier sind einige Spieldaten:
Hier benötigen wir die Daten in Langform; wir müssen also vom Breitformat zum Langformat pivotieren:
d_long <-
d_within %>%
pivot_longer(cols = y1:y3,
names_to = "time",
values_to = "y")
head(d_long)Es hilft (wie meistens), sich die Daten zu visualisieren, s. Abbildung 12.27.
p_y123_a <-
d_long %>%
ggplot(aes(x = time, y = y)) +
geom_jitter(width = .2)
p_y123_b <-
ggwithinstats(d_long,
x = time,
y = y,
results.subtitle = FALSE)
p_y123_a
p_y123_b
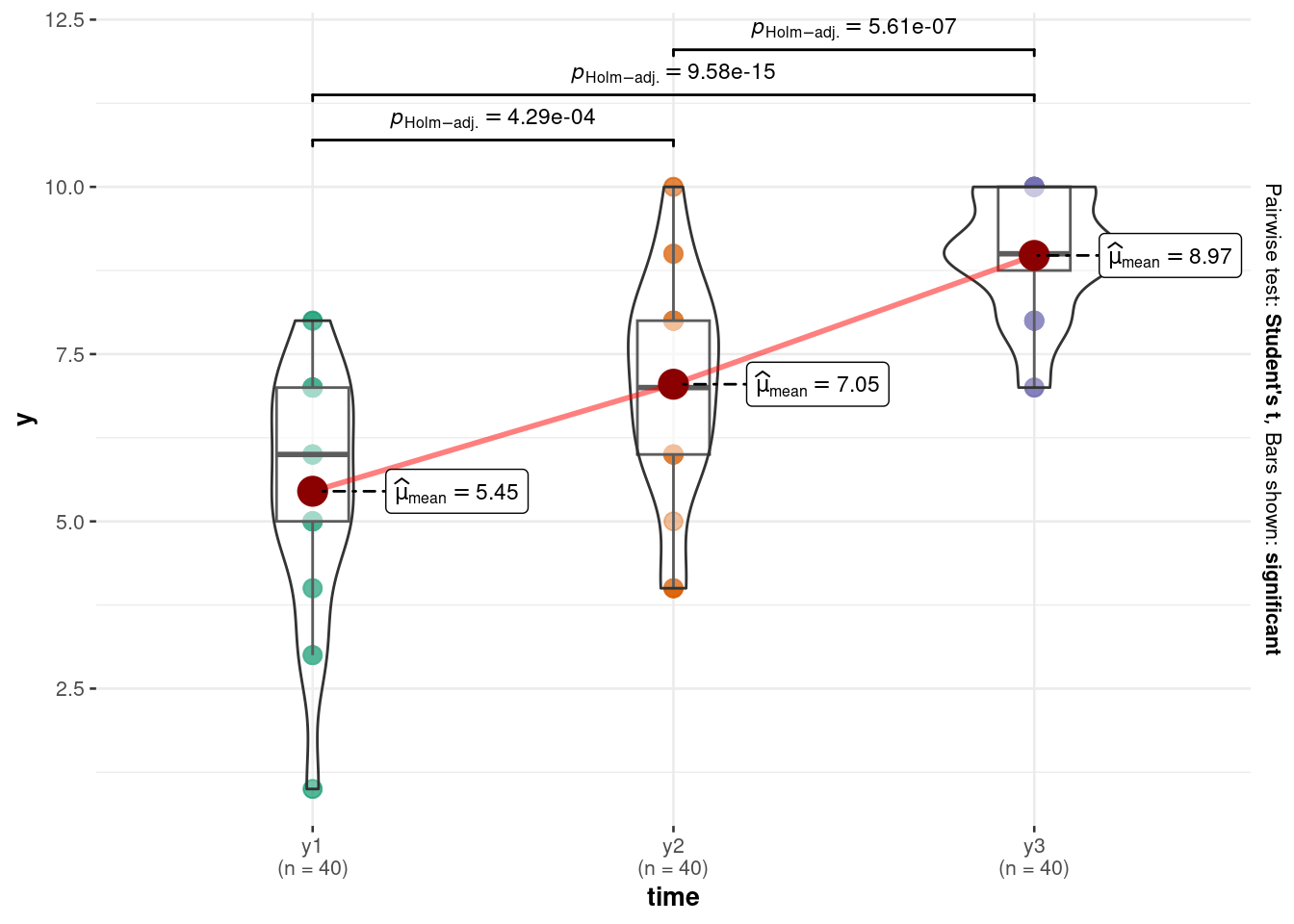
Berechnen wir die Mittelwerte von y pro Messzeitpunkte sowie die Veränderung von t1 zu t2 bzw. von t2 zu t3, s. Tabelle 12.8.
y pro Messzeitpunkte (y_mean) sowie die Veränderung von t1 zu t2 bzw. von t2 zu t3 (d)
| time | y_mean | d |
|---|---|---|
| y1 | 5.45 | |
| y2 | 7.05 | 1.60 |
| y3 | 8.97 | 1.92 |
12.9.4 Modellierung und Inferenz
m_within3 <- stan_lmer(y ~ 1 + (1 | time), data = d_long, refresh = 0)
summary(m_within3)
##
## Model Info:
## function: stan_lmer
## family: gaussian [identity]
## formula: y ~ 1 + (1 | time)
## algorithm: sampling
## sample: 4000 (posterior sample size)
## priors: see help('prior_summary')
## observations: 120
## groups: time (3)
##
## Estimates:
## mean sd 10% 50% 90%
## (Intercept) 7.3 1.2 5.9 7.2 8.6
## b[(Intercept) time:y1] -1.8 1.2 -3.2 -1.7 -0.4
## b[(Intercept) time:y2] -0.2 1.2 -1.6 -0.2 1.2
## b[(Intercept) time:y3] 1.7 1.2 0.3 1.7 3.1
## sigma 1.5 0.1 1.3 1.5 1.6
## Sigma[time:(Intercept),(Intercept)] 4.8 5.2 1.1 3.1 10.1
##
## Fit Diagnostics:
## mean sd 10% 50% 90%
## mean_PPD 7.2 0.2 6.9 7.2 7.4
##
## The mean_ppd is the sample average posterior predictive distribution of the outcome variable (for details see help('summary.stanreg')).
##
## MCMC diagnostics
## mcse Rhat n_eff
## (Intercept) 0.0 1.0 1270
## b[(Intercept) time:y1] 0.0 1.0 1291
## b[(Intercept) time:y2] 0.0 1.0 1289
## b[(Intercept) time:y3] 0.0 1.0 1287
## sigma 0.0 1.0 2699
## Sigma[time:(Intercept),(Intercept)] 0.1 1.0 1451
## mean_PPD 0.0 1.0 3897
## log-posterior 0.1 1.0 1096
##
## For each parameter, mcse is Monte Carlo standard error, n_eff is a crude measure of effective sample size, and Rhat is the potential scale reduction factor on split chains (at convergence Rhat=1).Die Schreibweise (1 | time) soll sagen, dass die Messwerte innerhalb von time verschachtelt sind und variieren. Die 1 sagt, dass es sich bei der variierenden Größe um den Intercept handelt, nicht um eine UV.
Ein “fixer” Effekt ist ein Effekt, für den kein Pooling stattfindet, das ist hier der Intercept.
Nur die festen (fixed) Effekte kann man sich so ausgeben lassen:
fixef(m_within3)
## (Intercept)
## 7.217592Im Durchschnitt werden ca. 7.1 Fragen richtig beantwortet (Gesamtmittel); das ist die Information die der Punktschätzer des Intercepts bietet.
Nur die Random-Effekte kann man sich so ausgeben lassen:
ranef(m_within3)
## $time
## (Intercept)
## y1 -1.7077278
## y2 -0.1826931
## y3 1.6952708
##
## with conditional variances for "time"Das sind jeweils die Abweichungen der Gruppenmittelwerte (y1, y2, y3) vom Gesamtmittel. Die Random-Effekte kann man sich visualisieren lassen, s. Abbildung 12.28.
plot(m_within3)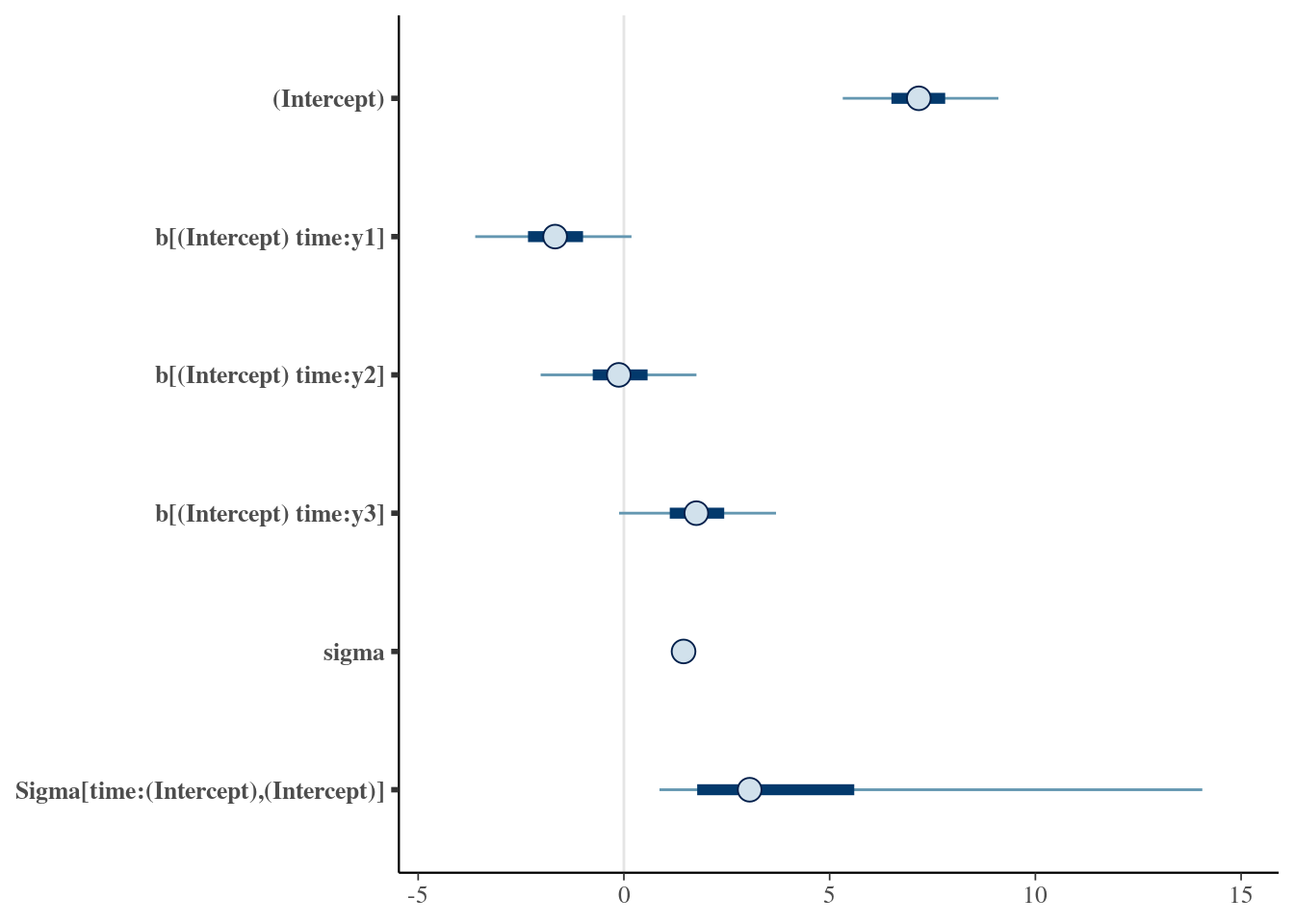
m_within3
12.10 Fazit
Unter Modellieren versteht man in der Forschungspraxis meist ein Regressionsmodell der Form av ~ uv. Die Inferenzstatistik hilft, die Modellparameter mit Schätzwerten für die Population zu versehen.
12.11 Aufgaben
Schauen Sie sich im Datenwerk die Aufgaben mit folgenden Tags an: