5 Beschreiben
Versuchsplanung, Statistik, R, Datenanalyse, Psychologie, Forschung
5.1 Lernsteuerung
5.1.1 tl;dr
In diesem Kapitel geht es um Studien mit dem Erkenntnisziel, eine Grundgesamtheit (Population) statistisch zu beschreiben: Es geht um Populationsbeschreibung. Ein Beispielstudie könnte das mittlere zur Verfügung stehende Finanzbudget von Studentis (pro Monat) untersuchen.
Wie hoch ist wohl das das monatliche Budget von Studentis an der Hochschule Ansbach?
5.1.2 Standort im Lernpfad
Abbildung 1.2 zeigt den Standort dieses Kapitels im Lernpfad und gibt damit einen Überblick über das Thema dieses Kapitels im Kontext aller Kapitel. Behalten Sie Ihren Fortschritt im Projektplan im Blick, s. Abbildung 1.3.
5.1.3 Benötigte R-Pakete
In diesem Kapitel benötigen Sie folgende R-Pakete.
5.1.4 Lernziele
- Sie können das Ziel einer Populationsbeschreibung von einer Explikation (kausale Erklärung) begrifflich trennen.
- Sie können erläutern, inwiefern die Inferenzstatistik benötigt wird, um die Ungewissheit einer Schätzung eines Populationsparamters zu quantifizieren.
- Sie können den benötigten Stichprobenumfang für gängige Situationen berechnen.
5.2 Was ist Populationsbeschreibung?
5.2.1 Definition
Definition 5.1 (Populationsbeschreibung) Populationsbeschreibung als Ziel einer wissenschaftlichen Studie ist eine Umsetzung von Beschreibung als epistemologisches Ziel, vgl. Abbildung 3.4. Studien dieser Art können eine, zwei oder mehr Variablen enthalten.\(\square\)
Beispiel 5.1 (Beispiele für populationsbeschreibende Fragen)
- Wie viel Geld hat ei Studenti in Deutschland aktuell (typischerweise) zur Verfügung im Monat?
- Haben weibliche Studentinnen mehr Geld zur Verfügung als männliche Studentis?
- Wie unterscheidet sich das Budget der Studentis nach Bundesland und nach Studienrichtung?\(\square\)
Beispiel 5.2 (1 Variable)
- Wie viel Geld hat ein Studenti in Deutschland aktuell (typischerweise) zur Verfügung im Monat?
- Wie viele Parties besucht ei Studenti im Schnitt pro Semester (in Deutschland, aktuell, in einem wirtschaftlichen Studiengang)?
- Wie groß ist der Anteil an Arbeitnehmern, die im Home-Office arbeiten (mind. 1 Tag pro Woche, aktuell, in De)?
- Wie groß ist der Anteil an Studentis, die heimlich nachts Statistik-Bücher lesen (mind. 30 Minuten, mind. 3 Nächte pro Woche, aktuell, in Deutschland …)?\(\square\)
Beispiel 5.3 (2 oder mehr Variablen)
- Haben Studentinnen mehr Geld zur Verfügung als (männliche) Studenten?
- Wie unterscheidet sich das Budget der Studentis nach Bundesland und nach Studienrichtung?\(\square\)
5.2.2 Notation
Forschungsfragen mit 1 Variable zur Populationsbeschreibung werden so notiert:
\[y \sim 1\] Forschungsfragen mit 2 Variablen (1 AV, 1 UV) zur Populationsbeschreibung werden so notiert:
\[y \sim x\]
Forschungsfragen mit 3 oder mehr Variablen (1 AV, 2 oder mehr UV) zur Populationsbeschreibung werden so notiert:
\[y \sim x_1 + x_2 + \ldots\]
5.2.3 Deskription ≠ Explikation
Vielleicht stammt die Weisheit von Chuck Norris, dass man in einer Studie mit dem Anspruch der (Populations-)Beschreibung keine Kausalinterpretationen treffen darf, s. Abbildung 5.1.

Beispiel 5.4 (Handynutzung beim Autofahren) Brown et al. (2021) untersuchen den Einfluss von Persönlichkeitsfaktoren beim Autofahren:
Young drivers exhibit high levels of risky driving behaviour, including texting while driving (TWD). The aim of this study was to examine the influence of personality (rash impulsivity, reward seeking), fear of missing out (FOMO) and mobile phone involvement (MPI) on frequency of TWD. Six hundred and twelve young drivers aged 17 to 24 years completed an online survey including these measures, and frequency of sending and reading TWD in the prior week. Rash impulsivity and reward seeking, as well as MPI, predicted both modes of TWD, while FOMO only predicted sending. In addition, rash impulsivity, reward seeking and FOMO all had significant indirect effects on sending and reading TWD via MPI. Findings highlight the importance of considering indirect relationships of personality via MPI on phone use while driving.
In ihrer Studie führen die Autoren Zusammenhänge zwischen verschiedenen Persönlichkeitsfaktoren und risikoreichem Fahrverhalten an, vermeiden es aber, kausale Schlussfolgerungen zu ziehen:
… a person higher on rash impulsivity may be more likely to both read and send a TWD (texting while driving).
“More likely” ist keine kausale Aussage, sondern ist eine Wahrscheinlichkeitsaussge, das hat nichts mit Kausalität zu tun.
An anderer Stelle schreiben die Autoren:
Rash impulsivity … will positively predict TWD.
“Will positively predict”, das hört sich zwar nach einer Prognose-Hypothese an, aber die Autoren berichten keine Statistiken der Prognose, sondern der Zusammenfassung, also ist es eine Deskriptions-Hypothesen.1
Das Berichten von Zusammenhängen ohne explizites Erwähnen Kausalhypothese einer Kausalhypothese heißt noch nicht, dass es sich um eine reine Deskriptionsstudie handelt. In vielen Fällen wird man an einer Kausalaussage interessiert sein: Hey, pack dein Handy weg, wenn du fährst, das ist super gefährlich. Implizit wird eine Kausalhypothese angestellt, da sich diese den Lesis aufdrängt. Faktisch haben viele Studien, die sich als Deskription ausgeben, eine Kausalhypothese.\(\square\)
🧑🎓 Darf ich eine Kausalhypothese aufstellen, auch wenn ich diese nicht richtig belegen kann? Oder muss ich dann eine Deskriptions-Hypothese aufstellen?
👨🏫 Man kann ohne Probleme eine Kausalhypothese aufstellen, auch wenn man diese nicht abschließend belegen kann. Kann sowieso keine (oder kaum eine) Studie. Man schreibt dann einfach, dass die vorliegende Studie keine abschließende Belege vorbringt, und dass alternative Schlüsse auch möglich sind.
5.3 Schätzen von Populationsparametern
5.3.1 Ungewissheit
Das Kreuz von fast allen Arten empirischer Studien: Wir wollen die Grundgesamtheit (Population) beschreiben, haben aber nur Daten über einen Teil der Population, also eine Stichprobe, s. Abbildung 5.2. Ungewissheit ist der Makel der empirischen Forschung.
Definition 5.2 (Ungewissheit in Populationsschätzungen) Eine Populationsschätzung nimmt eine Stichprobe als Grundlage, um einen Parameter (Kennwert) einer Population zu beschreiben. Daher sind Schätzungen mit Ungewissheit und somit Unsicherheit in den Parametern verbunden.\(\square\)
5.3.2 Deskriptiv- vs. Inferenzstatistik
Die Deskriptivstatistik fasst eine Wertereihe zu einer Kennzahl (Statistik) zusammen; die Inferenzstatistik schließt von einer Statistik auf die entsprechende Kennzahl (Parameter) einer Population, s. Abbildung 5.3.
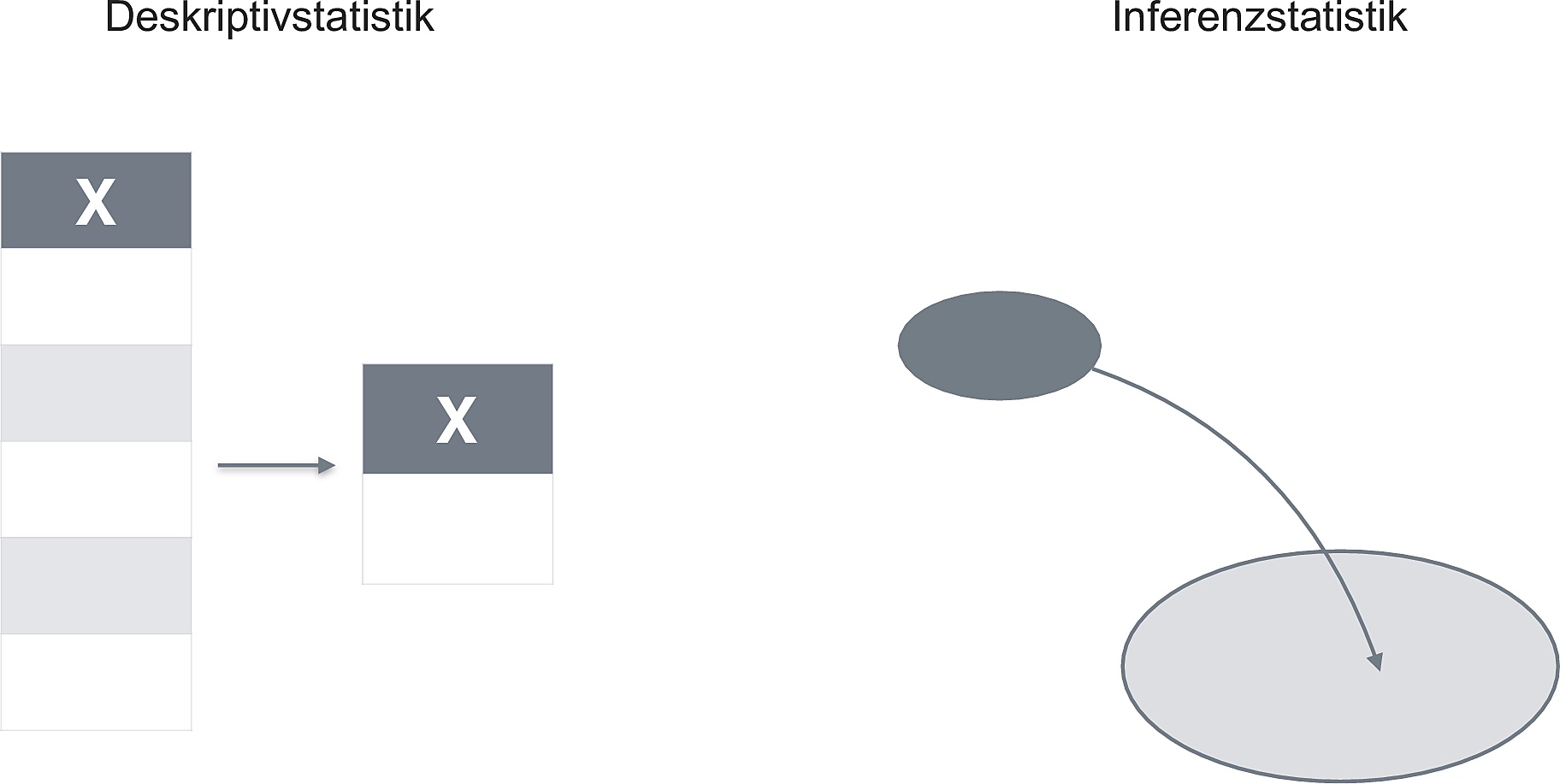
Beispiel 5.5 (Anteil der heimlichen Statistik-Fans?) Abbildung 5.3 illustriert an einem Beispiel den Unterschied zwischen Deskriptiv- und Inferenzstatsistik. Deskriptivstatistik errechnet eine Statistik: Den Anteil der heimlichen Statistikfans in der vorliegenden Stichprobe. Es gibt hier keine Ungewissheit: Wir haben alle Studis befragt und ihre Antwort aufgeschrieben.2 Die Inferenzstatistik schließt auf der Basis des Kennwerts und der Stichprobengröße auf die Population: Wie genau gibt die Statistik wohl den Anteil in der Grundgesamtheit wieder?\(\square\)
Der Schätzbereich ist das vielleicht wichtigste Werkzeug der Inferenzstatistik.
Definition 5.3 Ein Schätzbereich3 gibt einen Bereich plausibler Werte für einen Parameter an. In der Bayes-Statistik sind Aussagen erlaubt, die eine Wahrscheinlichkeit mit einem Wertebereich verbinden; in der Frequentistischen Statistik nicht.\(\square\)
Beispiel 5.6 Auf Basis unseres fiktiven Beispiels mit den heimlichen Statistikfans resümieren wir in unserer Inferenzanalyse, dass der 95%-Schätzbereich des Anteils von 0.32 bis 0.52 reicht.\(\square\)
Es gibt mehrere Varianten einens Schätzbereichs; in der Bayes-Statistik sind Perzentilintervalle ([PI; auch als Equal-Tail-Intervall, ETI bezeichnet]) und Intervalle höchster Dichte4 üblich.
Beispiel 5.7 (Spritverbrauch bei Automatik- vs. manuellem Getriebe) Wie groß ist der Unterschied im Spritverbrauch im Durchschnitt bei Automatik- vs. manuellem Getriebe?
Mit parameters() kann man sich die Schätzintervalle ausgeben lassen:
parameters(m1)Wie man erstreckt sich der 95%-PI-Schätzbereich5 von ca. 4 bis 11 Meilen pro Gallone Sprit. Dieses Ergebnis kann man so interpretieren:
Der Unterschied im Spritverbrauch in der Population wird auf [3.72, 10.70] (95%-ETI) geschätzt.
Oder, anschaulicher, man kann sich den Schätzbereich auch visualisieren lassen, s. Abbildung 5.4.
plot(parameters(m1))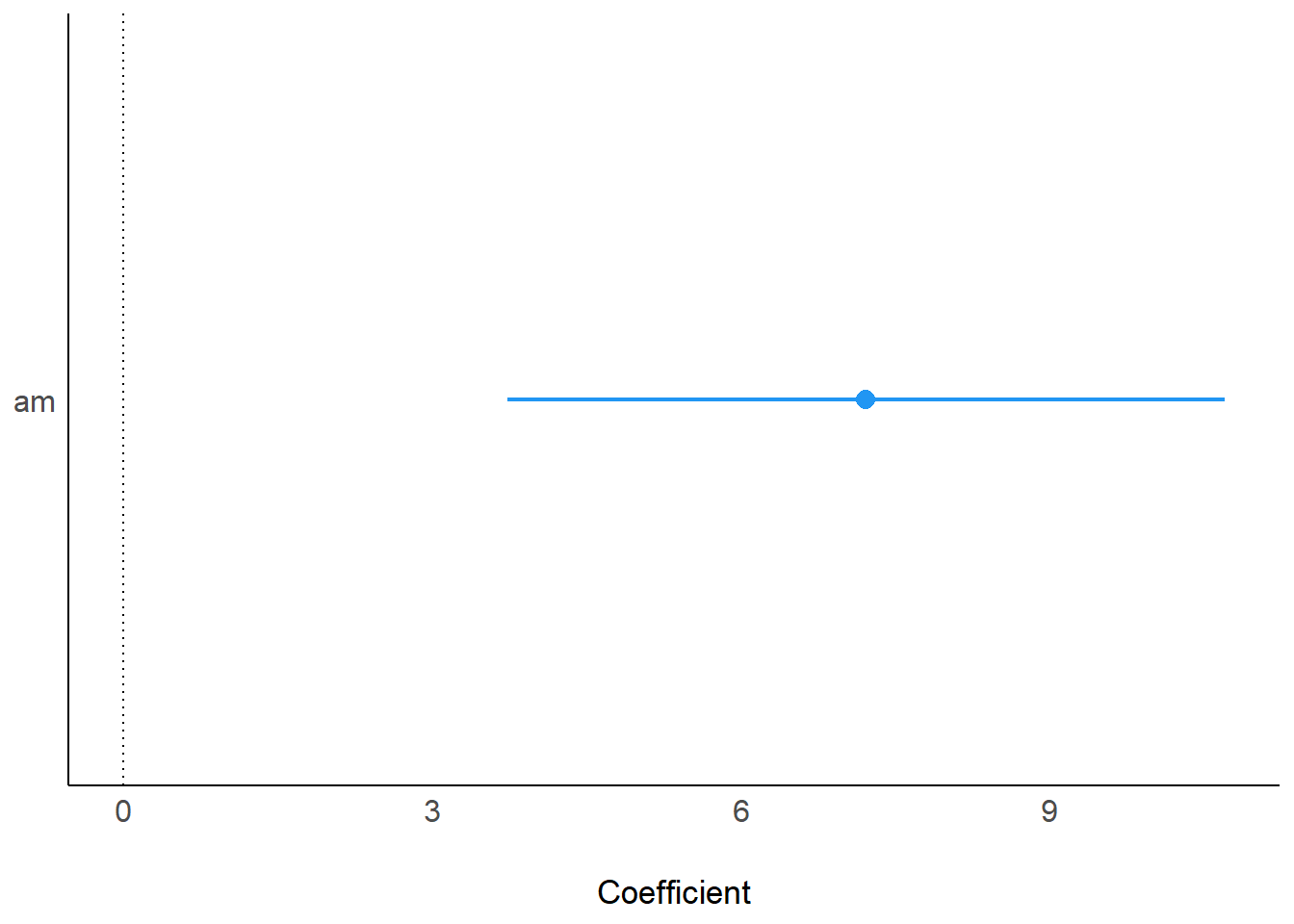
5.3.3 Eine gute Stichprobe anstelle einer Vollerhebung
Eine gute Stichprobe ist wie ein Löffelchen Suppe aus einem gut gerührten Topf, s. Abbildung 5.5. Um die Suppe abzuschmecken, reicht ein Löffelchen - eine kleine Stichprobe also.

5.3.4 Nomenklatur
Tabelle 5.1 stellt diese Buchstaben zusammen mit ihrer Aussprache und Bedeutung vor.
| Population | Aussprache | Stichprobe | Bedeutung in der Statistik |
|---|---|---|---|
| \(\beta\) | beta | b | Regressionskoeffizent |
| \(\mu\) | mü | m | Mittelwert |
| \(\sigma\) | sigma | s | Standardabweichung |
| \(\sigma^2\) | sigma-Quadrat | s | Varianz |
| \(\Sigma\) | Sigma | S | Summenzeichen |
| \(\rho\) | rho | r | Korrelation (nach Pearson) |
| \(\sigma\) | sigma | s | Streuung |
| \(\pi\) | pi | p | Anteil |
Mehr griechische Buchstaben finden sich hier.
5.3.5 Repräsentativität
Beispiel 5.8 (Gelegenheitsstichproben und Musikgeschmack) Schorsch erhebt seine Umfrage zu Musikpräferenzen Samstag Nacht um 23.50h vor der Nürnberger Disko Hirsch. Deva erhebt ihre Daten ihre Daten zur gleichen Zeit vor dem Nürnberger Opernhaus. Beide möchten den Musikgeschmack in der Nürnberer Population bestimmen. Ob ihre Stichproben wohl repräsentativ sind?6\(\square\)
Definition 5.4 (Gelegenheitsstichprobe) Eine Gelegenheits- oder Ad-hoc-Stichprobe ist das Resultat des Ziehens einer Stichprobe nach Praktikabilitätsgesichtpunkten. Anders gesagt: Man nimmt die erstbesten Personen in die Stichprobe auf - oder diejenigen, die einem am besten in den Kram passen.\(\square\)
Um mit Hilfe einer Stichprobenerhebung gültige Aussagen über ein Merkmal \(X\) in der avisierten Population treffen zu können, muss die Stichprobe repräsentativ sein.
Repräsentativ kann zweierlei bedeuten:
- Die Stichprobe ähnelt der avisierten Grundgesamtheit stark im zu messenden Merkmal
- Die Präzision der Schätzung ist messbar
Ein geeigneter Weg für eine repräsentative Stichprobe ist das Ziehen einer Zufallsstichprobe. Leider ist das oft nicht so einfach. Nur eine Zufallsstichprobe erlaubt es, die Präzision einer Stichprobe anhand statistischer Verfahren zu bestimmen. Allerdings gibt es auch Situationen, in denen eine Adhoc-Stichprobe einer Zufallsstichprobe ähnlich (genug) ist.\(\square\)
Beispiel 5.9 (Warum keine Adhoc-Stichprobe?)
Forschungsfrage: Wie viel Zeit verbringt ein deutscher Bürger (m/w/d) am Tag im Schnitt am Handy?
Nennen wir diese Variable, mittlere Zeit pro Stunden am Tag an einem Mobilgerät, \(X\).
Wir befragen dazu die nächstbesten 100 Menschen am Hauptbahnhof, Samstagabend, 23h.
Ob wir mit einer Adhoc-Stichprobe (am Hauptbahnhof) die Population für X repräsentativ erfassen? Vermutlich nicht, denn
Junge Menschen oder Nicht-Berufstätige sind womöglich überrepräsentiert in dieser Stichprobe, und ihr Handykonsum unterscheidet sich vielleicht deutlich von der Gesamtbevölkerung
Hiesige Menschen sind vermutlich am hiesigen Hauptbahnhof überrepräsentiert, und ihr Handykonsum unterscheidet sich vielleicht von den Auswärtigen
…
Vermutlich gibt es weitere Verzerrungen (Konfundierungen, Kollisionsvariablen) die uns nicht bekannt sind, aber eine Rolle spielen\(\square\)
5.4 Fallbeispiel: World Happiness Report
Der World Happiness Report berichtet und diskutiert die Lebenszufriedenheit der Menschen in vielen Ländern. Es handelt sich um eine Studie mit dem Anspruch der Populationsbeschreibung.
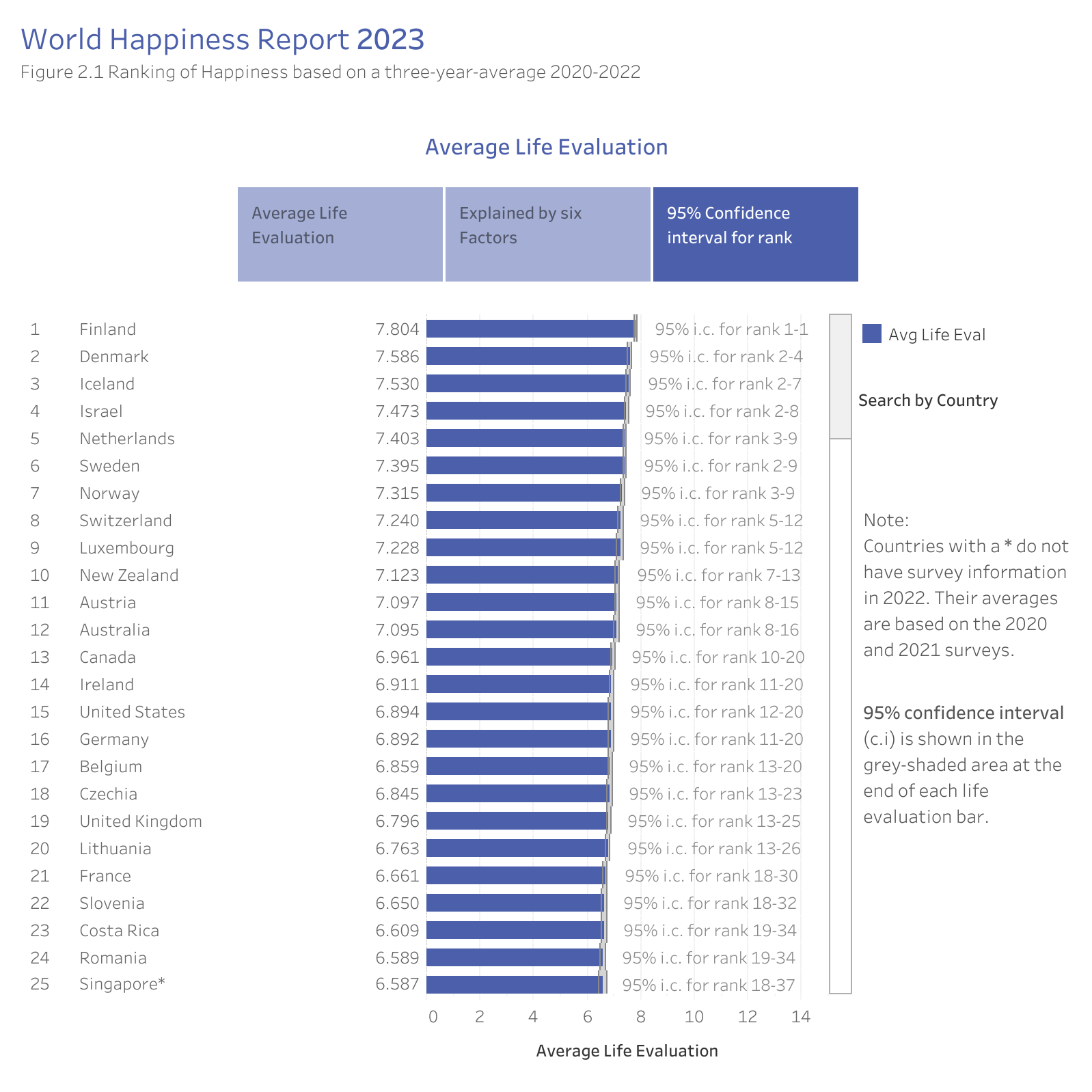
Abbildung 5.6 zeigt die mittlere Lebenszufriedenheit in den 25 zufriedensten Ländern. Neben dem Mittelwert, der als Balken dargestellt ist7, ist das Konfidenzintervall (95%) dargestellt. Man erkennt es an dem kleinen grauen Kästchen am rechten Ende des jeweiligen Balkens. Diese Konfidenzintervalle sind Angaben zur Schätzgenauigkeit des Modells, d.h. des jeweiligen Mittelwerts. Man kann das Konfidenzintervall so interpretieren, dass es einen Bereich plausibler Werte für den Modellparameter (hier: mittlere Zufriedenheit) angibt. Da die Genauigkeit einer Schätzung abhängig ist von der Stichprobengröße und die Stichprobengröße (aufgrund des Zusammenwerfens der Daten mehrerer Jahre) relativ groß ist, sind die Konfidenzintervalle relativ klein, die Schätzung also recht präzise. Zumindest mutet das Diagramm so an. Allerdings ist auch angegeben, dass die Schätzinteralle überlappen. So sieht man, dass sich die Bereiche plausibler Werte für die Plätze 2-4 (Dänemark, Island, Israel) überlappen. Man kann also argumentieren, dass die Rangfolge z. B. dieser drei Länder nicht sicher ist.
5.5 Typische Forschungsdesigns
Da Studien mit Ziel der Populationsbeschreibung per Definition keine Treatment-Wirkungen untersuchen, sind die entsprechenden Studien nur auf Beobachtung (Informationsaufnahme) und nicht Intervention abgestellt. Beobachtungsstudien sind häufig einfacher strukturiert als Studien mit Treatment. Der Versuchsaufbau einer querschnittliche Studie mit Ziel der Populationsbeschreibung ist simpel: Sie messen pro Beobachtungseinheit alle relevanten Variablen.
Beispiel 5.10 (Einkommen von Studentis) Sie interessiert die Forschungsfrage, wie viel Geld Studentis im Monat als Einkommen zur Verfügung haben. Dazu befragen Sie \(n=300\) Studentis. Um eine möglichst zufällige oder zumindest repräsentative Studie zu gewinnen, haben Sie eine Nachricht im Forum des Studiengangs gepostet: Wer bei Ihrer Befragung mitmacht, den laden Sie zur nächtsen Party ein. Außerdem verlosen Sie ein Abendessen mit Ihnen. Sicherlich wird der Andrang groß sein.\(\square\)
Definition 5.5 (Forschungsdesign) Unter dem Forschungsdesign (synonym: Versuchsplan) versteht man den Aufbau einer Studie. Speziell meint man damit den Aufbau insoweit er die Variablen betrifft, die in der Forschungsfrage oder den Forschungsfragen vorkommen.\(\square\)
5.5.1 Univariate Forschungsfragen
Univariate (nur eine Variable) Forschungsfragen untersuchen nur eine einzelne Variable.
Beispiel 5.11 (Mittlere Körpergröße deutscher Männer) Fragt eine Studie nach der mittleren Körpergröße deutscher Männer, so liegt eine univariate Studie mit dem Ziel der Populationsbeschreibung vor.\(\square\)
Entsprechend einfach sind die Studiendesigns solcher Forschungsfragen, s. Abbildung 5.7.
flowchart LR A[Begrüßung und Aufklärung</br>der Probanden] --> B[Messung der Körpergröße] B --> C[Messung soziodemografischer</br>Variablen] C-->D[Verabschiedung]
5.5.2 Gruppenvergleich
Viele Studien mit Gruppenvergleich haben ein explikatives Ziel; es gibt aber Gruppenvergleich-Studien mit dem Ziel der Populationsbeschreibung.
Beispiel 5.12 (Verfügbares Budget von Studentis im Vergleich von Studiengängen) Fragt eine Studie nach dem verfügbaren Finanzbudget von Studentis in Abhängigkeit des Studiengangs - vergleicht die Studie also das Budget zwischen den Studiengängen - so liegt eine Deskriptionsstudie mit Gruppenvergleich vor, s. fig-gruppenvergleich.\(\square\)
flowchart LR A[Begrüßung und Aufklärung</br>der Probanden] --> B[Abfrage des Budgets] B --> B2[Abfrage des Studiengangs] B2 --> C[Messung soziodemografischer</br>Variablen] C-->D[Verabschiedung]
Die Studie zum World Happiness Report ist ebenfalls ein Beispiel für einen Gruppenvergleich.
5.6 Effektstärke
Was ist ein “großer” Effekt, was ein “kleiner” (oder “mittlerer”?)
Definieren wir als “groß” den Unterschied in mittlerer Körpergröße zwischen einem 6 Jahre alten und einem 7 Jahre alten Mädchen. Beziehen wir uns auf die typische Körpergrößen von Mädchen dieses Alters.
Mittlere Körpergröße:
- 6.0 Jahre: 115 cm
- 7.0 Jahre: 121 cm
Die SD liegt bei ca. 5.5 cm.
Demnach beträgt der Größenunterschied 6 cm, oder ca. 1 SD-Einheit.
Aus der oben zitierten Größentabelle können wir ablesen:
- 6 Jahre, 6 Monate: 118 cm
Das ist ein Unterschied von 3 cm, oder ca. 1/2 SD-Einheit. Nennen wir das einen “mittleren” Effekt.
5.7 Planung der Stichprobengröße
Wie groß “muss” eine Stichprobe sein, damit man einen Effekt findet (wenn er denn da ist), am besten mit einer gewissen (hohen!) Genauigkeit? Die Beantwortung solcher Fragen nennt man auch Poweranalyse und ist im Folgenden in Grundzügen dargestellt.
5.7.1 Schätzung eines normalverteilten Parameters
Sagen wir, wir möchten einen normalverteilten Parameter \(X\) mit “hinreichender Genauigkeit”, \(e\) schätzen. Dazu müssen Sie Annahmen treffen zur Verteilungsform und zur Streuung von \(X\).
Beispiel 5.13 (Mittlere Daddelzeit) Sagen wir, um es konkret zu machen, uns interessiert die Zeit, die mittelfränkische junge Erwachsene pro Tag am Handy verbringen (“mittlere Daddelzeit”). Um uns Tipperei zu sparen, geben wir dieser Variablen den Namen \(X\).
Aus einer Vor-Untersuchung schätzen wir für die Population eine Streuung \(\sigma\) der Daddelzeit von 20 (Minuten). Außerdem gehen wir davon aus, dass \(X\) normalverteilt ist.
Gesucht. Wir möchten gerne wissen, wie groß die Stichprobe sein muss, um \(X\) mit einem 95%-KI der Breite von \(b=8\) Minuten zu schätzen.
Der Radius8 \(r=b/2\) eines Konfidenzintervalls (KI) hier so berechnet werden:
\[r = \frac{z \cdot \sigma} {\sqrt{n}}\]
Für ein 95%-KI ist der zugehörige z-Wert in der Normalverteilung 1.96.
{kind=link}
In unserem Fall ist ein Radius (auch Fehler \(e\) genannt) von \(r=e= b/2=4\) gesucht; das Konfidenzintervall soll einen Radius von kleiner oder gleich diesem Wert aufweisen:
\[\frac{z \cdot \sigma} {\sqrt{n}} \le e \Rightarrow \frac{z^2\sigma^2}{e^2} \le n \]
Die Stichproben muss also diese Mindestgröße \(n_{min}\) aufweisen:
\[n_{min} = \frac{z^2\sigma^2}{e^2}\]
Lassen wir R die schnöde Rechenarbeit erledigen:
z <- 1.96 # z-Wert für 95%-KI
s <- 20 # Streuung, Sigma
e <- 4 # Radius von 4 Minuten
n <- (z^2*s^2) / e^2
n
## [1] 96.04Unsere Stichprobe sollte also (mindestens) 97 Beobachtungseinheiten umfassen, um den Parameter mit der angegebenen Genauigkeit zu messen. Voraussetzung ist natürlich eine Zufallsstichprobe.
Damit man nicht selber ausrechnen muss, kann man auch eine Tabelle bemühen, etwa die von Bortz & Döring (2006), s. Abbildung 5.9.

In Abbildung 5.9 ist \(e\) als Anteil der Streuung von \(\sigma\) dargestellt.
Beispiel 5.14 (Mittlere Daddelzeit 2) Bei einem Fehler von 8 Minuten und einer Streuung von 20 Minuten ergäbe sich ein relativer Schätzfehler von 8/20 = 2/5 = .4 (unter der Annahme einer Normalverteilung und einer Zufallsstichprobe.)\(\square\)
Manchmal kennt man die Streuung nicht, aber der Range, \(R\), (max-min) ist bekannt. In diesem Fall schlagen Bortz & Döring (2006) folgende Formel vor, um die Streuung \(\sigma\) zu schätzen:
\[\sigma = \frac{R}{5.15}\]
Wenn Sie die Streuung des Merkmals \(X\) nicht aus der Literatur ableiten können, können Sie sich behelfen, in dem Sie die Ausprägung von \(X\) bei \(n=20\) Versuchspersonen messen. Dann messen Sie wieder 20 Versuchspersonen. Sind beide Streuungen ähnlich, so haben Sie einen Schätzwert für die Streuung in der Population. Sind sie unähnlich, so erheben Sie weitere 20 Personen (Bortz & Döring, 2006). \(\square\)
5.7.2 Schätzung für Korrelationen
Schönbrodt & Perugini (2013) untersuchten mittels einer Simulationsstudie, ab welcher Stichprobengröße Korrelationswerte \(\rho_0\) stabil werden. “Stabil” soll heißen, dass wiederholte Ziehungen einer Stichprobe aus einer Population mit Korrelation \(\rho_0\) die Stichprobenwerte der Korrelation “nicht mehr so viel variieren”, z. B. weniger als 0.1 Korrelationseinheiten. Ihre allgemeine Schlussfolgerung war, dass \(n=250\) einen guter Grenzwert darstellt, s. Abbildung 5.10.
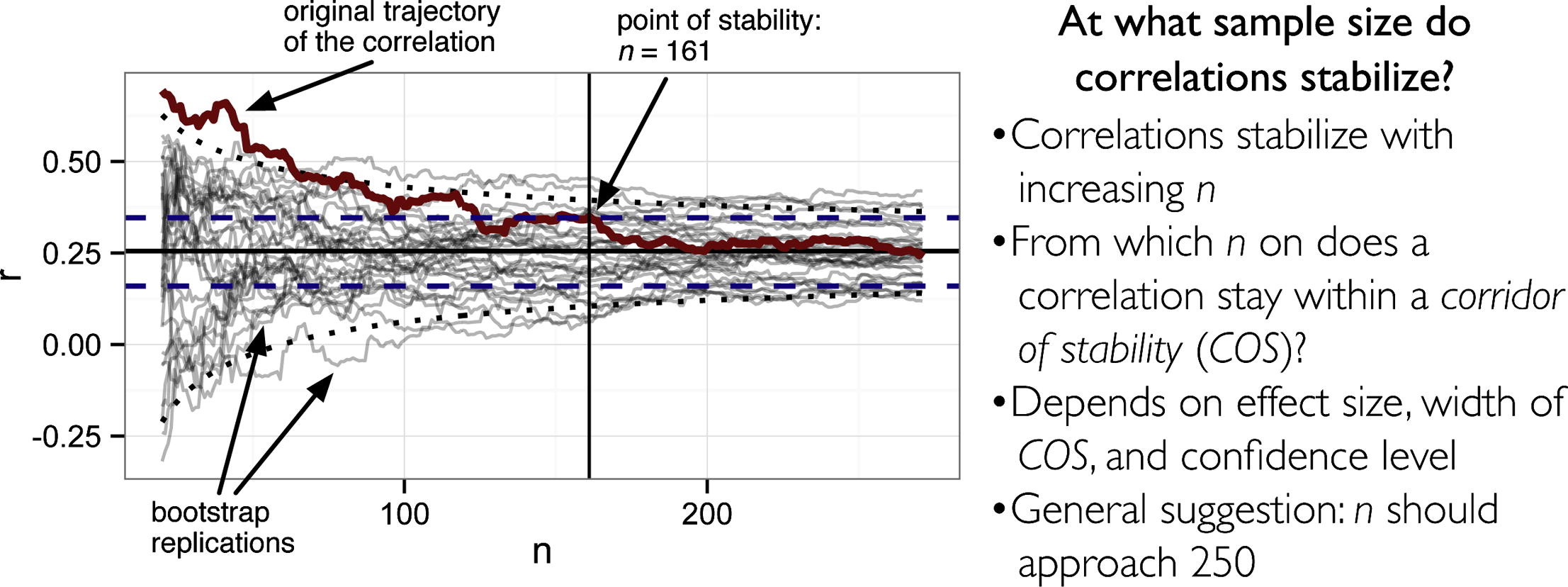
Ausführlichere Empfehlungen sind Abbildung 5.11 zu entnehmen (Schönbrodt & Perugini, 2013). Dort sind die Mindest-Fallzahlen \((\text{COS}_{\text{crit}})\) in Abhängigkeit des Konfidenz-Niveaus (80%, 90%, 95%) und der wahren Korrelation \(\rho\) in der Population zu entnehmen.

5.7.3 Stichprobengrößen für Nullhypothesentests
Der Einfachheit halber begnügen wir uns mit der Analyse von Cohen (1992). Der Autor errechnet (die Untergrenze von) Stichprobenumfänge, um mit einer Wahrscheinlichkeit von 80% einen Effekt zu finden, die Nullhypothese also zu verwerfen. Dabei hängt diese Wahrscheinlichkeit von der Größe des Effekts ab, s. Tabelle 5.2.
| Effektstärke | klein | mittel | groß |
|---|---|---|---|
| Cohen’s \(d\) (Mittelwertunterschied) | 0.20 | 0.50 | 0.80 |
| r (Korrelation) | 0.10 | 0.30 | 0.50 |
| \(f^2\) (multiple Regression) | 0.02 | 0.15 | 0.35 |
| \(\eta^2\) (ANOVA, ungefähr) | 0.01 | 0.06 | 0.14 |
| \(f\) (ANOVA) | 0.10 | 0.25 | 0.40 |
Dabei gilt:
\(\eta^2 = \frac{SS_{\text{Effekt}}}{SS_{\text{gesamt}}}\), in R
eta_squared(mein_aov_modell), aus dem Paketeasystats\(f^2 = \frac{R^2}{1 - R^2}\), in R mit
r2(mein_lm), aus dem Paketeasystats
Auf dieser Basis leitet der Autor folgende (Mindest-)Stichprobenangrößen ab, s. Tabelle 5.3. Dabei typische Annahmen getroffen (\(\alpha = .05\), \(\beta=.2\)).
| Test | klein | mittel | groß |
|---|---|---|---|
| \(t\)-Test (unabhängig, zweiseitig) | 394 | 64 | 26 |
| \(t\)-Test (gepaart) | 199 | 34 | 15 |
| Korrelation (\(r\)) | 783 | 85 | 29 |
| ANOVA (1 Faktor, 4 Gruppen) | 180 | 44 | 28 |
| \(\chi^2\)-Test (df = 1) | 785 | 88 | 32 |
Für Regressionen hängt die Stichprobengröße nicht nur von der Effektgröße, sondern auch von der Anzahl der Prädiktoren (\(k\)) ab, s. Tabelle 5.4.
| Prädiktoren (k) | klein | mittel | groß |
|---|---|---|---|
| 1 (= r) | 783 | 85 | 29 |
| 2 | 481 | 67 | 30 |
| 3 | 547 | 76 | 34 |
| 4 | 599 | 84 | 38 |
| 5 | 645 | 91 | 42 |
| 6 | 686 | 97 | 45 |
| 7 | 726 | 102 | 48 |
| 8 | 757 | 107 | 50 |
Die hier angegebenen Stichprobengrößen beziehen sich auf das Ziel, mit 80% Wahrscheinlichkeit einen Effekt (von angegebener Größe: klein, mittel, groß) zu entdecken. Damit ist noch nichts über die Präzision der Parameterschätzung gesagt. Die Stichprobengrößen sind also nur gedacht für das bescheiderene Ziel der Schätzung, ob ein Effekt ungleich 0 ist. Möchte man die wissen, wie viele Versuchspersonen man benötigt, um einen Effekt mit einer bestimmten Genauigkeit zu schätzen, würde man mehr Versuchspersonen benötigen. Das R-Paket effectsize, Teil von easystats, bietet Hilfen zur Klassifizierung von Effektstärken.
5.7.4 Umsetzung mit R
5.7.4.1 Für Nullhypothesen
Um die minimale Stichprobengröße für einen mittleren Effekt von \(f^2\) zu berechnen, kann man die Funktion pwr.f2.test verwenden, etwa so:
pwr.f2.test(u=5, f2=0.1/(1-0.1), sig.level=0.05, power = .8)
##
## Multiple regression power calculation
##
## u = 5
## v = 115.1043
## f2 = 0.1111111
## sig.level = 0.05
## power = 0.8Dabei gilt:
-
u: Anzahl der Prädiktoren (UV) im Modell -
f2: Effektgröße definiert als \(R^2 / (1-R^2)\) -
sig.level: Das Signifikanzniveau, per Standard oft 5% -
power: Die statistische Power (\(1-\beta\)) -
vliefert die Stichprobengröße: \(N = v + u + 1\)
5.7.4.2 Für Konfidenzintervalle
Bei \(u=5\) Prädiktoren und einem erwarteten R-Quadrat von 0.3 wird folgende Stichprobengröße benötigt, wenn man das Konfidenzintervall von \(R^2\) auf 0.1 begrenzen möchte:
u <- 5
r2 <- .3
ss <- sample_size_for_r2(u = u, r2 = r2) # aus dem R-Paket prada
ss |> select(N)5.8 Welche Variablen soll ich in meine Regressionsanalyse aufnehmen?
Nehmen Sie (zusätzlich zur AV) folgende Variablen in Ihr Regressionsmodell auf:
- Alle UVs
- ggf. weitere Kovariaten
Definition 5.6 (Kovariate) Eine Kovariate ist eine Variable, die in ein statistisches Modell aufgenommen wird, um zusätzliche Varianz der abhängigen Variable zu erklären oder Störeinflüsse zu kontrollieren, ohne selbst die zentrale interessierende unabhängige Variable zu sein. \(\square\)
Es bietet sich an, weitere Prädiktoren in eine Regression aufnehmen, wenn sie: - Confounding kontrollieren - Residualvarianz reduzieren (Parameter werden genauer geschätzt) - Moderation testen (Interaktionen) - theoretisch begründet sind
Nicht aufnehmen, wenn: - sie durch die UV verursacht sind (Mediator) - sie sowohl eine Wirkung der UV als auch der AV ist (Collider) - keine theoretische Begründung vorliegt - Stichprobe zu klein ist
Eine Kovariate sollte:
- zeitlich vor der UV liegen
- mit UV UND AV zusammenhängen können
- nicht durch die UV verursacht sein
- theoretisch begründet sein
Eine Kovariate, die die Bedingungen nicht erfüllt, sollte nicht als in das Modell aufgenommen werden.
5.9 Literatur
Eine klassische Einführung in das Thema Planung psychologischer Studien liefert Bortz & Döring (2006).
Leider nicht sehr präzise formuliert von den Autoren.↩︎
Unter der Annahme, die Messung ist fehlerfrei; insbesondere unter der Annahme, alle Studis haben ehrlich geantwortet. Es ist zu hoffen, dass niemand muss seine Liebe geheimhalten muss.↩︎
Es gibt viele Synonyme oder ähnliche, nicht immer scharf definierte Begriffe: Schätzbereich, Vertrauensintervall, Konfidenzintervall…↩︎
Highest Density Inteval, HDI↩︎
Wie man der Hilfeseite des Befehls entnehmen kann, wird im Standard per Voreinstellung ein PI bzw. ETI ausgegeben.↩︎
Nein.↩︎
eine Praxis, von der man nur abraten kann, s. Friends Don’t Let Friends Make Bar Plots for Means Separation↩︎
Der “Radius” eines Konfidenzintervalls ist die Hälfte der Breite des Konfidenzintervalls.↩︎